第四章 贪心
活动安排
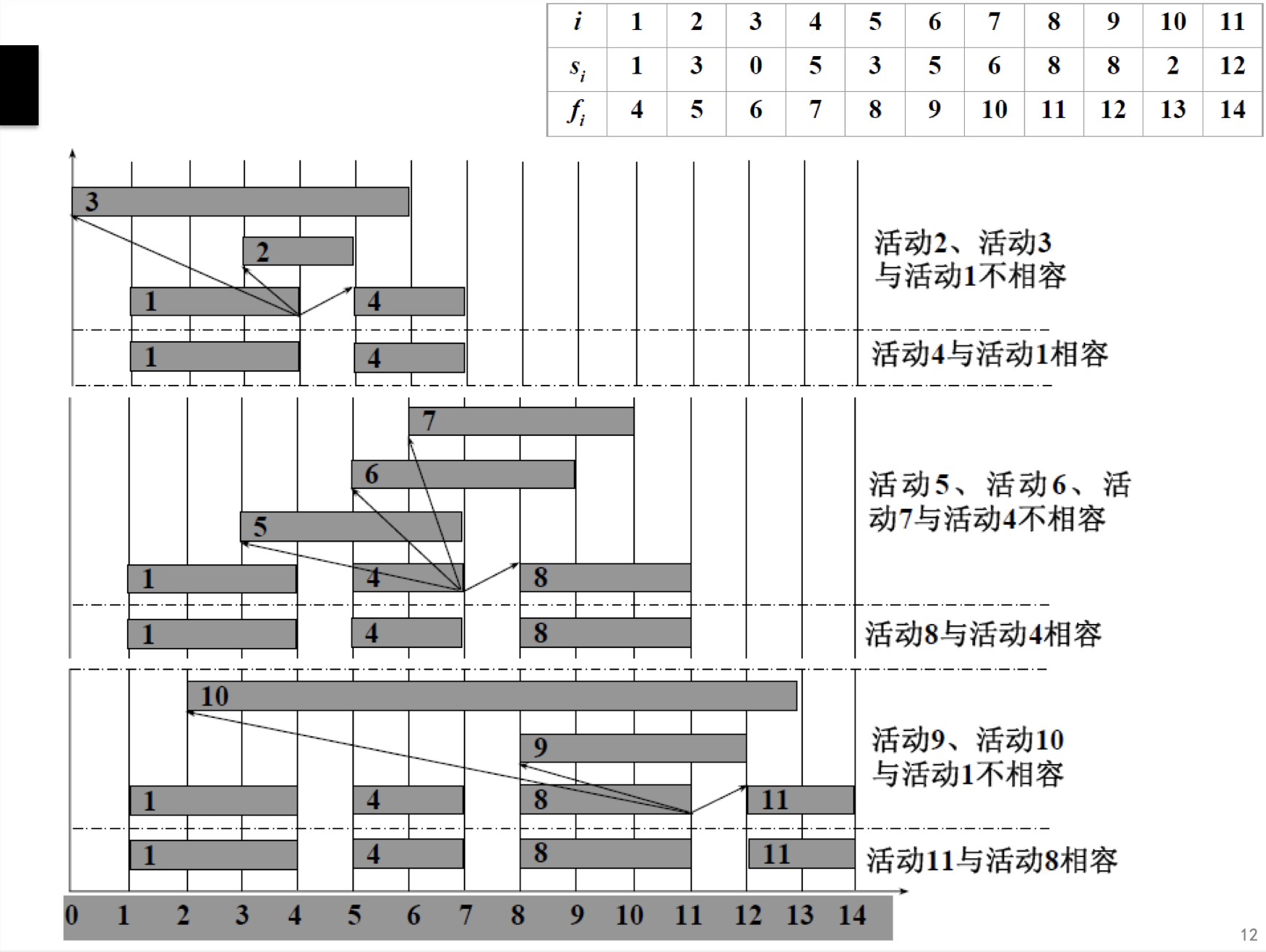
给出的是各个活动的开始时间s,结束时间f
- 首先,按结束时间f以递增顺序排序
- 然后,顺序选择选择大于第一个活动的结束时间的开始时间,找到对应的活动
- 安排选择到的这个活动,然后继续上一步操作,直到在活动集合中选择出最大的相容活动子集合
1
2
3
4
5
6
7
8
9
10
11
12
13
| void eventOrganizer(int event[],int startTime[],int finalTime[],bool select[],int num) {
int currentEvent = 1;
select[1] = true;
for(int i = 2;i <= num;i++) {
if(startTime[i] >= finalTime[currentEvent]) {
currentEvent = i;
select[i] = true;
} else {
select[i] = false;
}
}
}
|
T(n)=O(n)如果加上排序,T(n)=O(nlogn)
证明:贪心最优解




两个贪心要素
贪心选择性质

贪心选择性:每一步贪心选出来的一定是原问题的最优解的一部分
最优子结构性质


最优子结构:每一步贪心选完后会留下子问题,子问题的最优解和贪心选出来的解可以凑成原问题的最优解
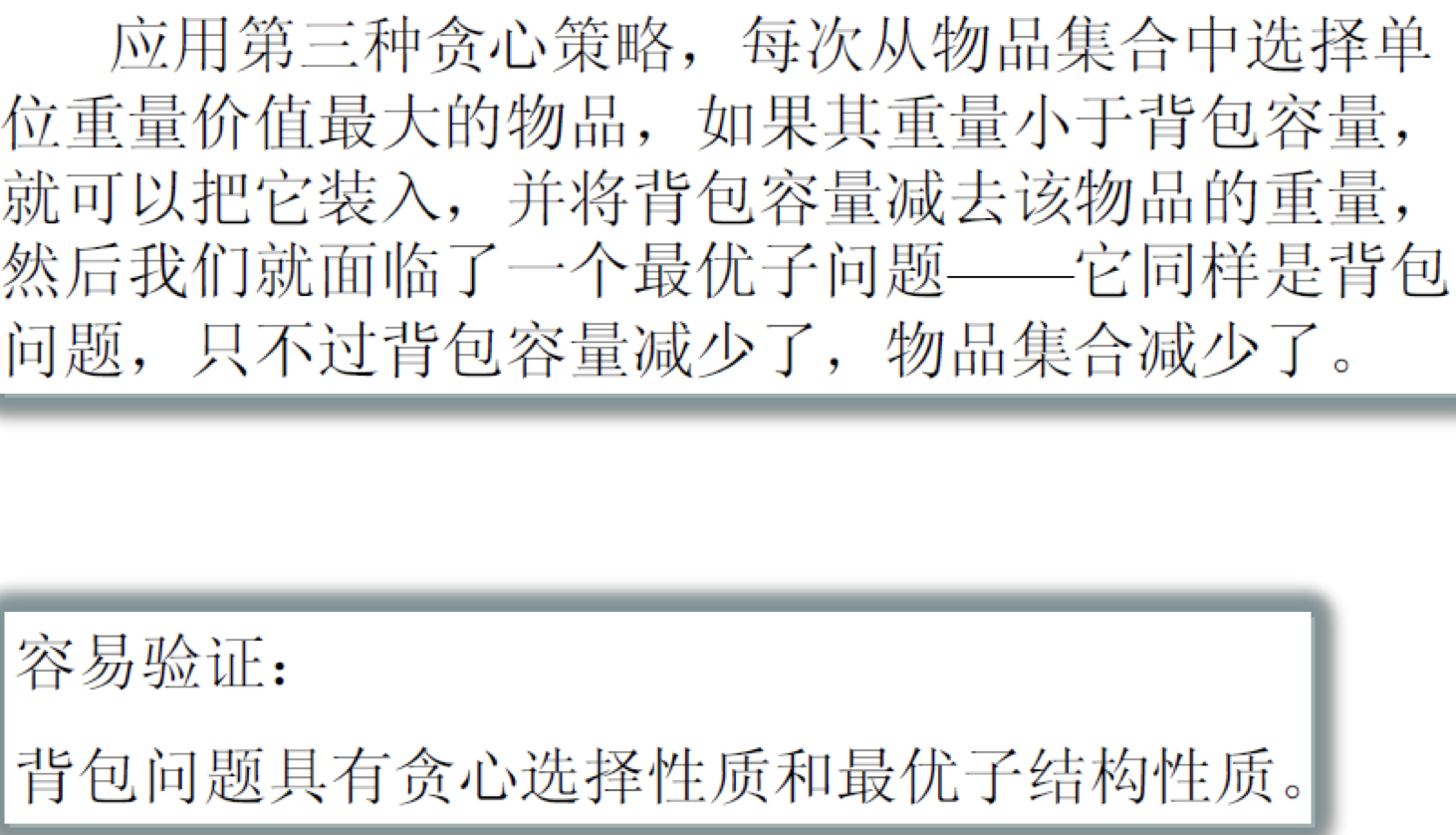
背包问题
区别于0-1背包问题,0-1背包问题不能使用贪心算法,因为它无法保证背包一定被填满


1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| double bucket(vector<Good> &goodList, double volume) {
double valueSum = 0;
int i = 0;
sort(goodList.begin(), goodList.end(),
[](Good A, Good B) { return A.unitPrice > B.unitPrice; });
for (i = 0; i < goodList.size(); i++) {
if (goodList[i].weight <= volume) {
valueSum += goodList[i].value;
volume -= goodList[i].weight;
goodList[i].percent = 1;
} else {
break;
}
}
if (i < goodList.size() && volume > 0) {
valueSum += volume / goodList[i].value;
goodList[i].percent = volume / goodList[i].weight;
}
return valueSum;
}
|
T(n)=O(n)如果加上排序,T(n)=O(nlogn)
最优装载问题
类似于背包问题,只不过价值统一为1,且不能分装
也就是说,总是选择重量最轻的物品,因为他们单位价值最高




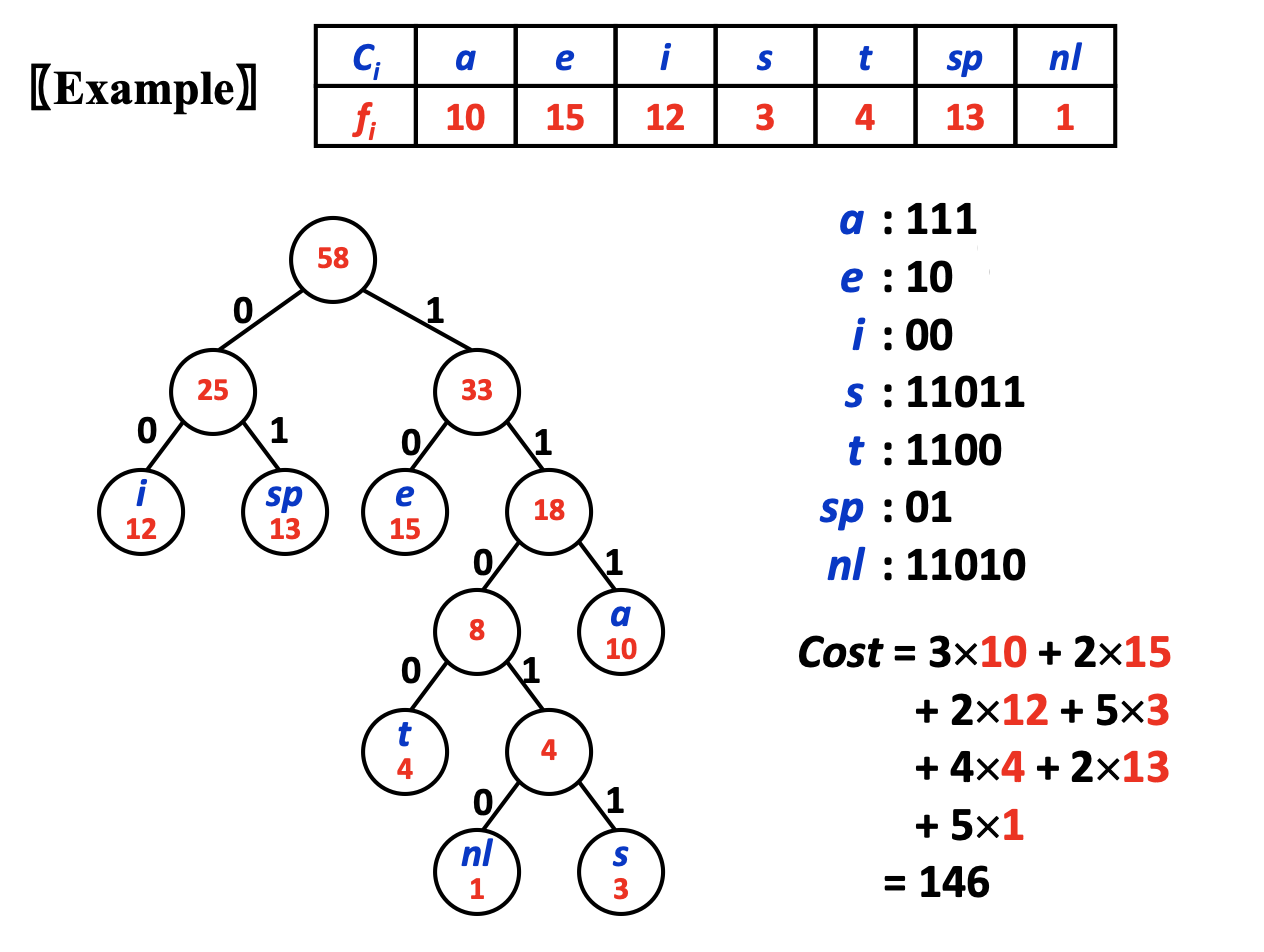
哈夫曼编码
1
2
3
4
5
6
7
8
9
10
11
12
13
| void Huffman ( PriorityQueue heap[], int N ) {
for ( i = 1; i < N; i++ ) {
创建一个新节点C;
从堆中取出最小值节点,作为C的左子节点;
从堆中再取出最小值节点,作为C的右子节点;
C的节点值 = 左子节点值 + 右子节点值;
将C放入堆中,然后从小到大排序;
}
}
|
构建哈夫曼树的时间复杂度取决于构建树的方法,这里使用的是最小堆(最小优先队列)
构建最小堆的时间复杂度为O(nlogn),每次取出两个最小的值创建新的节点的时间为O(logn),故总时间复杂度为
T(n)=O(nlogn)
编码的时间复杂度是由叶子节点的数量决定的。每个节点编码需要的时间为O(logn),因此全部n个节点完成编码需要
T(n)=O(nlogn)
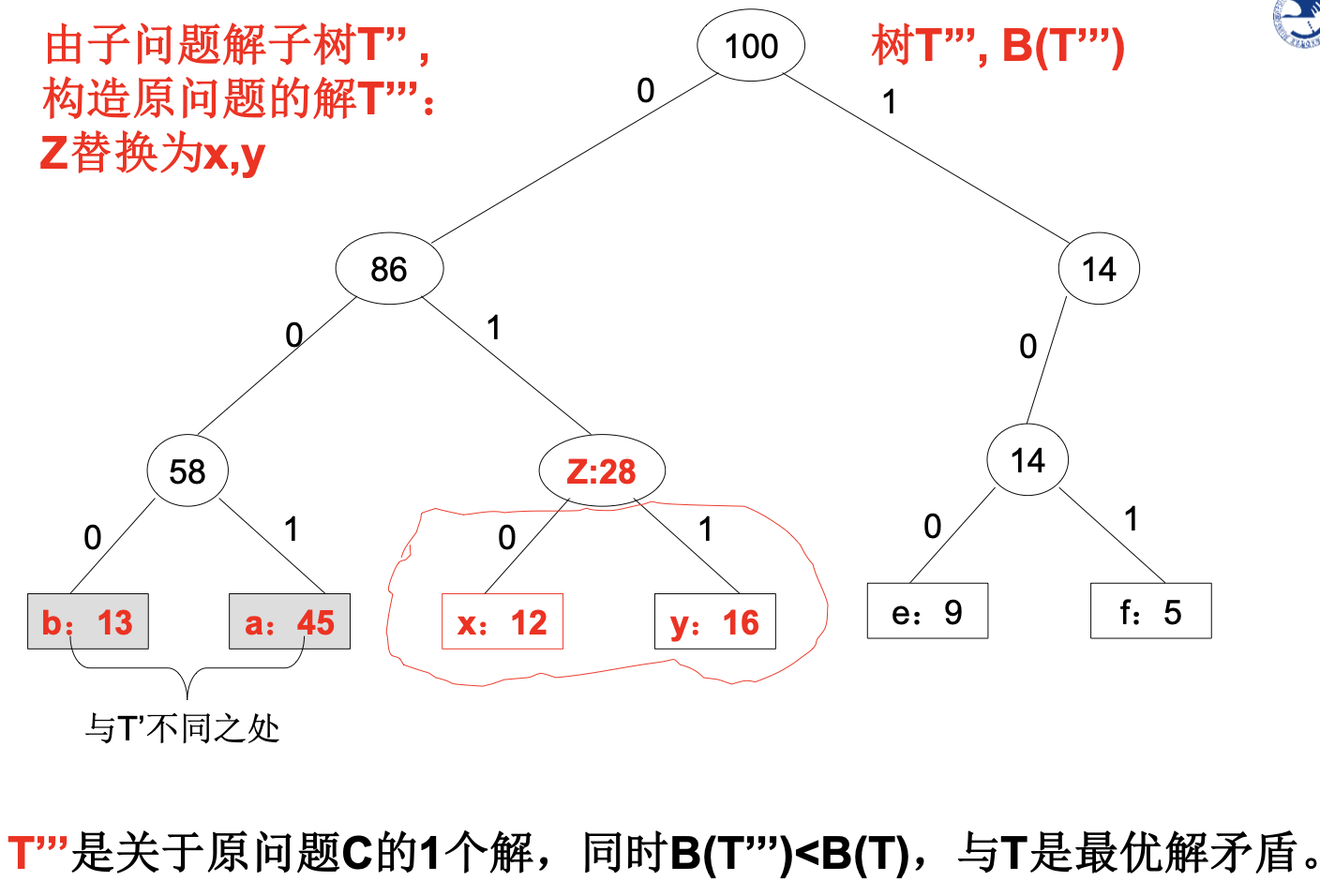
贪心选择性的证明
证明思路: 设字符集C的1个最优前缀码表示为二叉树T 。 采用一定方法,将T修改新树T’,使得
- 在T’中具有最小频率的x和y是最深叶子,且互为兄弟
- T’还是C的最优前缀。
这样x、y在最优前缀码T’中只有最后一位不同。
假设:b、c是T中最深叶子且互为兄弟,f(b)<=f©;
已知:C中2个最小频率字符f(x)<=f(y),但在T中,x、y有可能并非最深结点!!
由于x、y具有最小频率,故f(x)<=f(b), f(y)<=f©
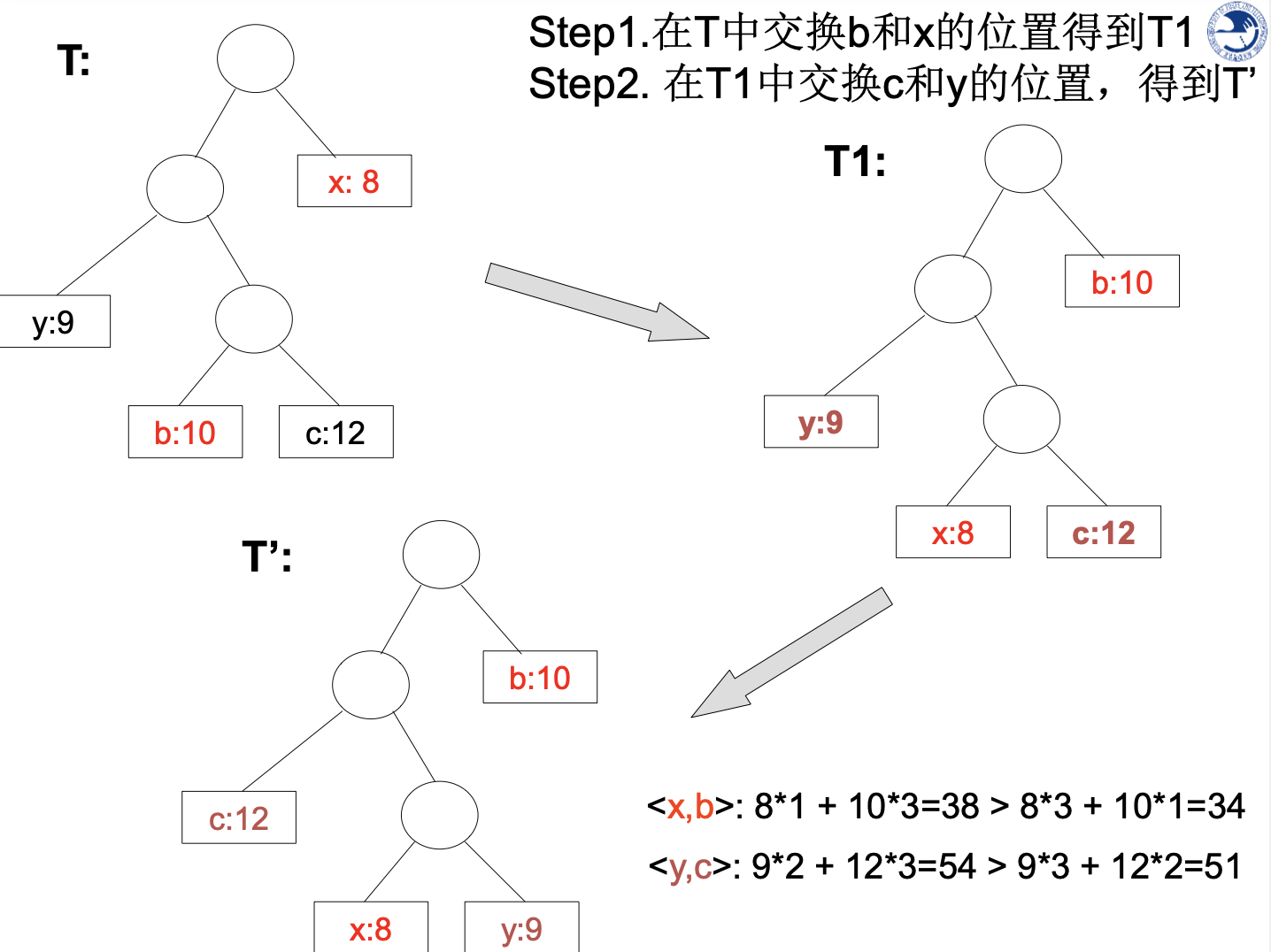
可以证明:
- B(T)—B(T1) ≤0,即第一步交换不会增加平均码长
- B(T1)—B(T’) ≤0,即第二步交换也不会增加平均码长
故T’的码长仍然是最短的,即T’是最优前缀码,并且其最小频率的x、y具有最深的深度(最长的编码),且只有最后一位不同。
最优子结构的证明
需要证明:
给定字符集C和其对应的最优前缀码T,可以从中得到子问题C’ (C的子集)及其对应的最优前缀子树T’
构造性证明:
对T中2个互为兄弟的叶节,点x、y,其父节点为z。
将z看做频率为f(z) = f(x) + f(y)的字符,则T’=T-{x,y}是子问题$C’=(C-{x,y}) \cup {z} $的最优编码
证明关键点:
- T的平均码长B(T)可用子树T’的平均码长B(T’) 表示,即 B(T) = B(T’) + 1*f(x) + 1*f(y)
上式即为递推表达式,表示原问题最优值与子问题最优值之间的关系
迪杰斯特拉
对有向图G=(V,E)
其基本思想是,设置顶点集合S并不断地作贪心选择来扩充这个集合。一个顶点属于集合S当且仅当从源到该
顶点的最短路径长度已知。
初始时,S中仅含有源。设u是有向图G的某一个顶点,把从源到u且中间只经过S中顶点的路称为从源到u的特殊路径,并用数组dist记录当前每个顶点所对应的最短特殊路径长度。
Dijkstra算法每次从V-S中取出具有最短特殊路长度的顶点u,将u添加到S中,同时对数组dist作必要的修改
一旦S包含了所有V中顶点,dist就记录了从源到所有其它顶点之间的最短路径长度。
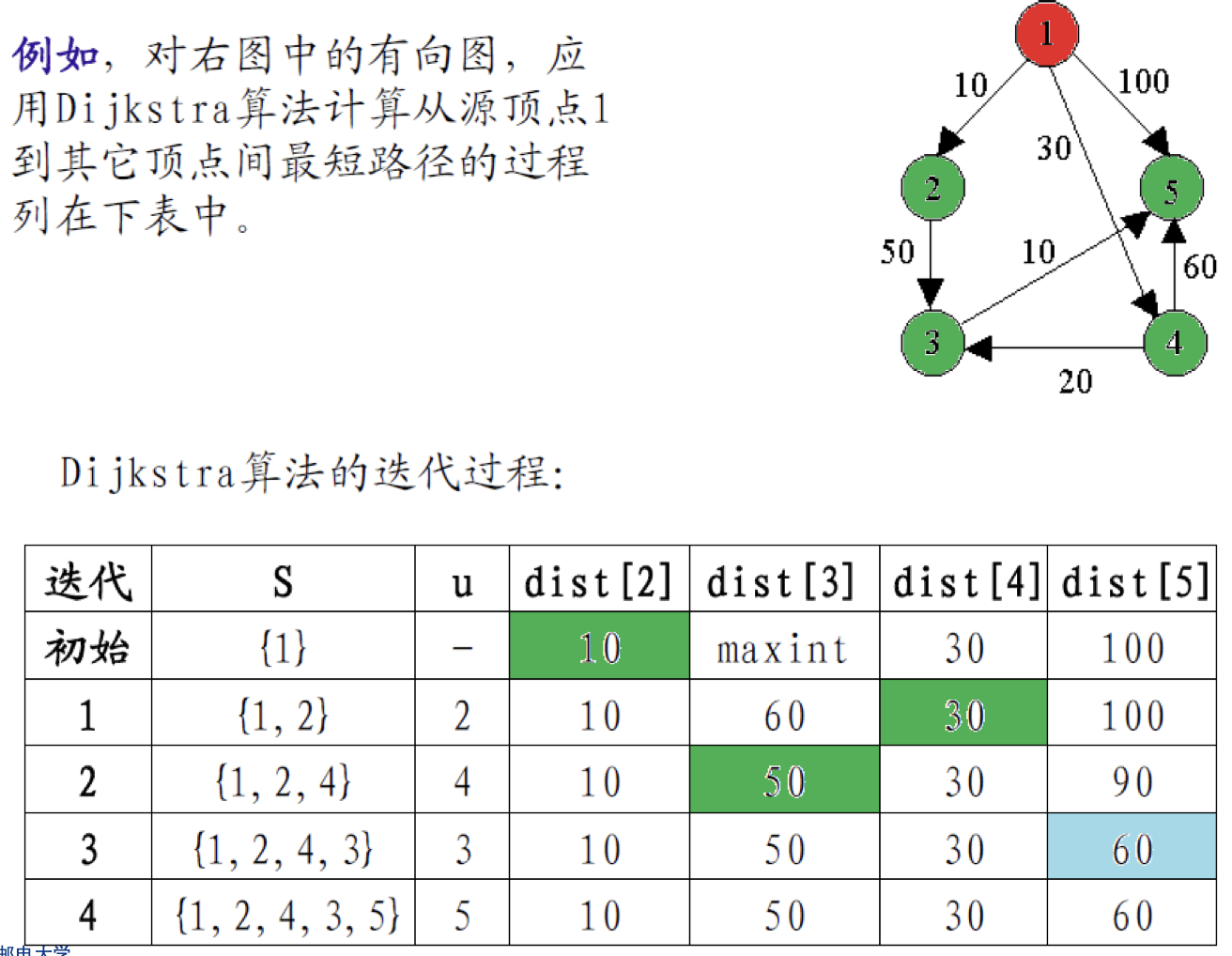
算法特点:迭代过程中,每个节点u的**dist[u]**值是非递增的
用带权邻接矩阵表示具有n个顶点和e条边的带权有向图G(V,E).
Diikstra算法的主循环体需要O(n)时间。这个循环需要执行n-1次,所以完成彼环需要O(n2)时间。
算法的其余部分所需要时间不超过O(n2)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
#define INF 99999
void initMap(vector<vector<int>> &map) {
for (int i = 0; i < map.size(); i++) {
map[i][i] = 0;
}
}
int dijkstra(vector<vector<int>> &map) {
vector<int> distList(map.size(),INF);
distList[0] = 0;
vector<bool> visitList(map.size(), false);
for (int i = 0; i < map.size() - 1; i++) {
int node = -1;
for (int j = 0; j < visitList.size(); j++) {
if (!visitList[j] && (node == -1 || distList[j] < distList[node])) {
node = j;
}
}
visitList[node] = true;
for (int j = 0; j < map.size(); j++) {
distList[j] = min(distList[j], distList[node] + map[node][j]);
}
}
if(distList[distList.size() - 1] == INF) {
return -1;
} else {
return distList[distList.size() - 1];
}
}
int main() {
fstream fInput("dijkstra.in", ios::in);
fstream fOutput("dijkstra.out", ios::out);
if (fInput.is_open()) {
int pointNum, edgeNum;
fInput >> pointNum >> edgeNum;
vector<vector<int>> map(pointNum, vector<int>(pointNum, INF));
initMap(map);
for (int i = 0; i < edgeNum; i++) {
int pointA, pointB, weight;
fInput >> pointA >> pointB >> weight;
map[pointA - 1][pointB - 1] = weight;
map[pointB - 1][pointA - 1] = weight;
}
fOutput << dijkstra(map);
}
fInput.close();
fOutput.close();
}
|
贪心选择策略
在每步迭代时,从V-S中选择具有最短特殊路径dist[u]的顶点u,加入S
贪心选择性证明
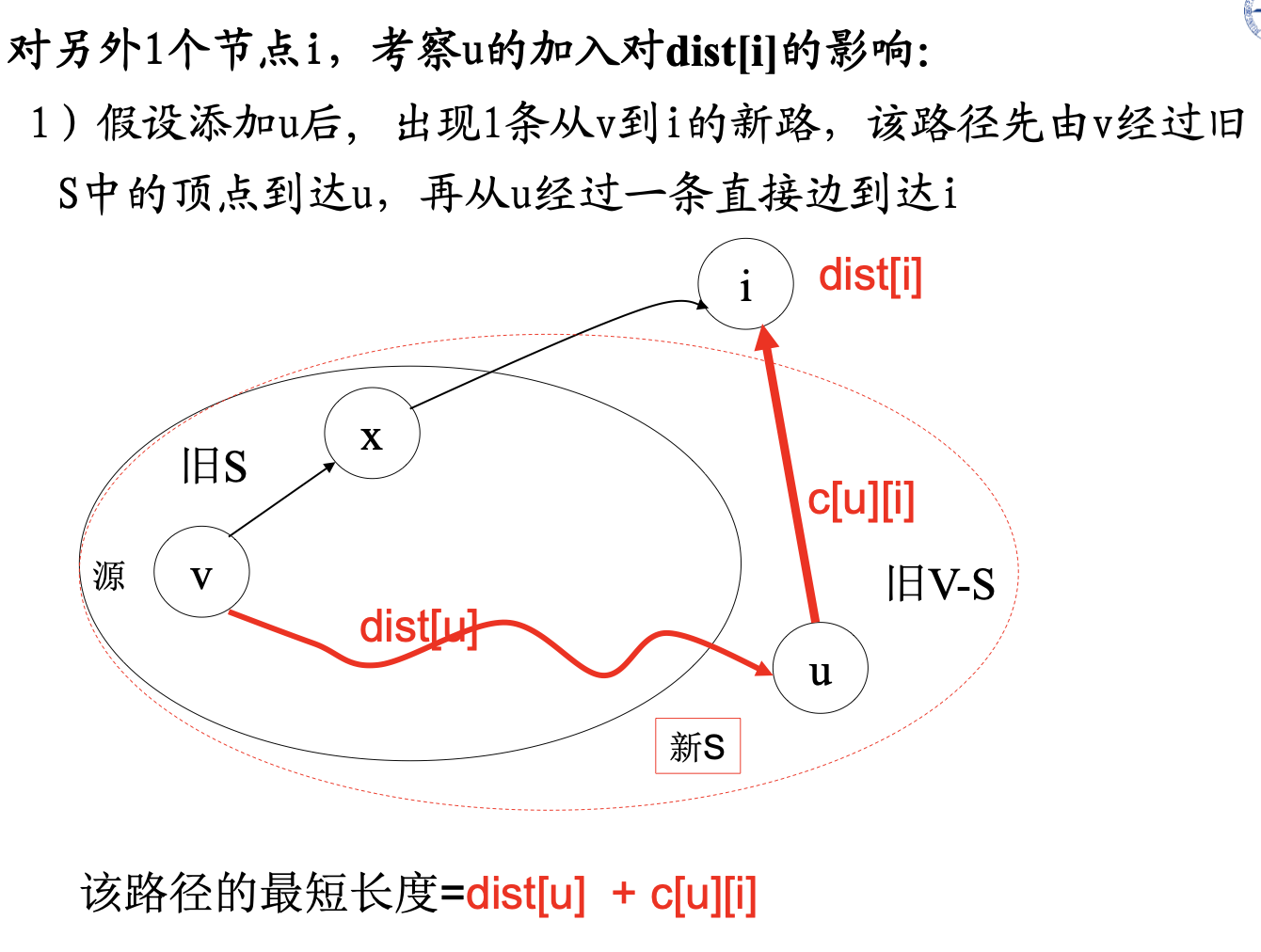
需证明对顶点u,从v开始、经过G中任意顶点到达u的全局最短路径的长度d(v, u) = 从v开始、只经过S中顶点到达u的最短路径的长度dist(u)
即不存在另一条v到u的最短路径,该路径上某些节点x在V-S 中,且该路径的长度 d(v,u)<dist[u].
反证法
假设:
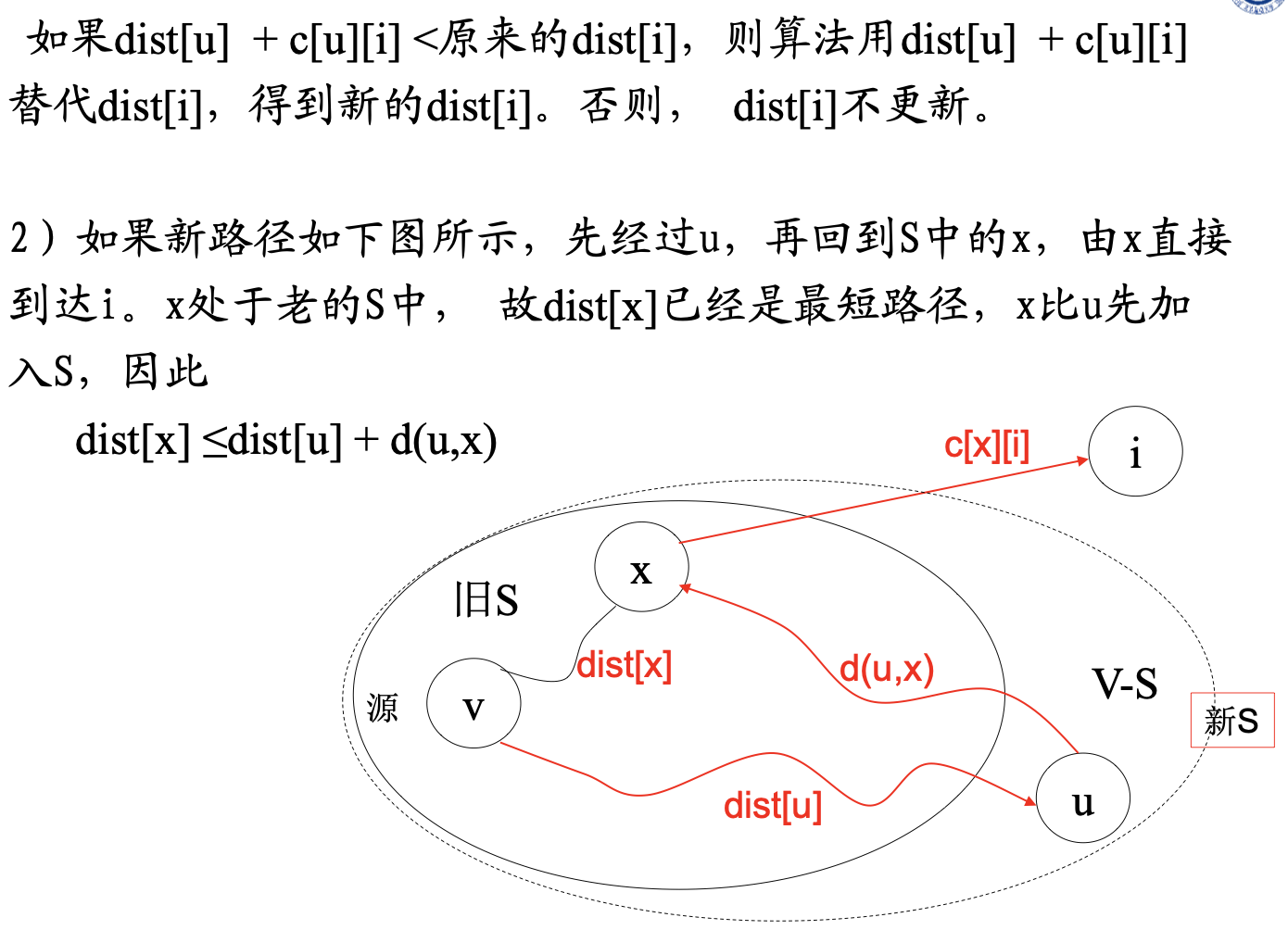
- 在迭代求解过程中,顶点u是遇到的第1个满足:d(v, u) < dist[u]的顶点
- 从v到u的全局最短路径上,第1个属于V-S的顶点为x
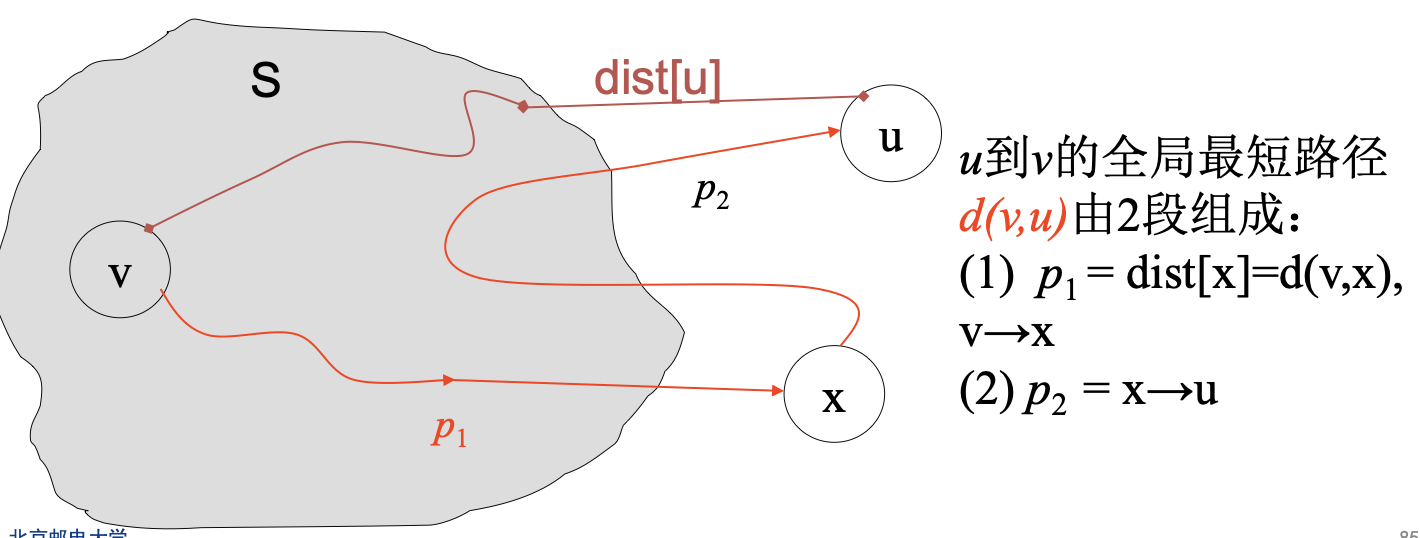
首先,因为u是第一个满足全局最短路径不完全在S集合中的顶点, 即d(v, u) < dist[u], 而x是在u之前遇到的顶点,x的最短路径完全在S中,因此,dist[x] = d(v,x) ≤ d(v, u)
对v到u的全局最短路径,有d(v, x)+ distance(x, u)= d(v ,u)< dist[u]
由于distance(x,u)>0,因此dist[x]= d(v, x)< d(v ,u)< dist|u],
即 dist[x]< dist[u]
但是根据路径p构造方法,在上图所示情况下,u,x都在集合S之外,即u,x都属于V-S,但u被选中时,并没有选x(由u的全局最优路径的特性可知),根据扩展S的原则选dist最小的顶点加入S,说明此时:
dist[u]≤ dist[x],这与前面推出的dist[x]< dist[u]相矛盾,反证成功
最优子结构性质
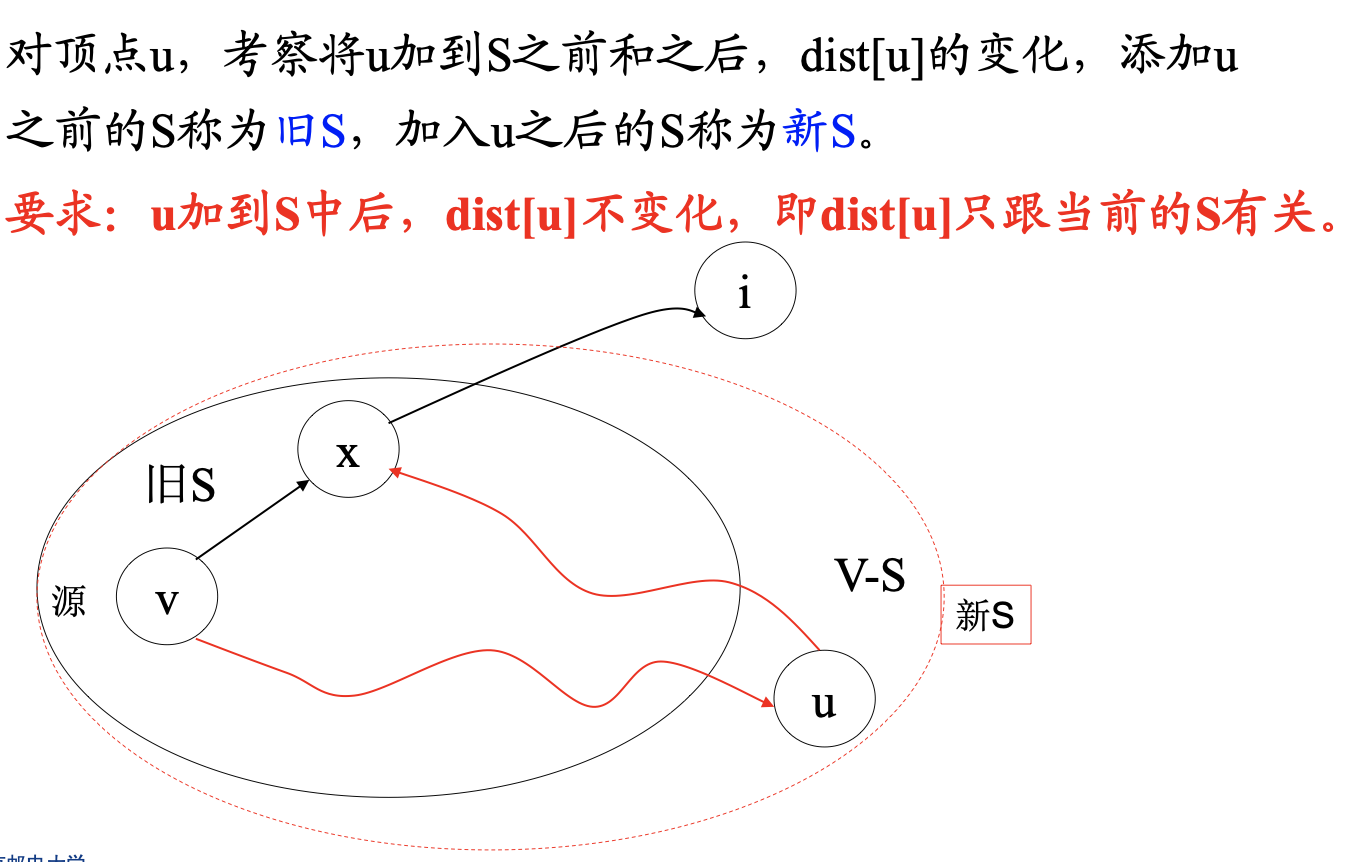

最小生成树
都利用了最小生成树**(MST)** 性质:
设G=(V, E)是连通带权图,顶点集U是V的真子集。 如果
-
(u,v)∈E为横跨点集U和V-U的边,即u∈U,v∈V−U,
-
在所有这样的边中,(u,v)的权c[u][v]最小, 则一定存在G的一棵最小生成树,它以(u,v)为其中一条边,即(u,v)出现在最小生成树中
说明:真子集U可以任意选取
使用反证法证明MST成立:
假设对G的任意一个最小生成树T,针对点集U和V-U, (u,v)∈E为横跨这2个点集的最小权边, T不包含该最小权边 <u, v>,但T包括节点u和v。
将<u, v>添加到树T中,树T将变为含回路的子图,并且该回路上有一条不同于<u, v> 的边<u’, v’>, u’ ∈U, v’ ∈V-U
将<u’, v’>删去,得到另一个树T’,即树T’是通过将T中的边<u’, v’>替换为<u,v> 得到的。
由于这2条边的耗费满足c[u][v] ≤c[u’][v’],因此用较小耗费的边 <u,v>替换后得到的树T’的耗费更小,即:
T’耗费≤ T的耗费
这与T是任意最小生成树的假设相矛盾
最小生成树之Prim
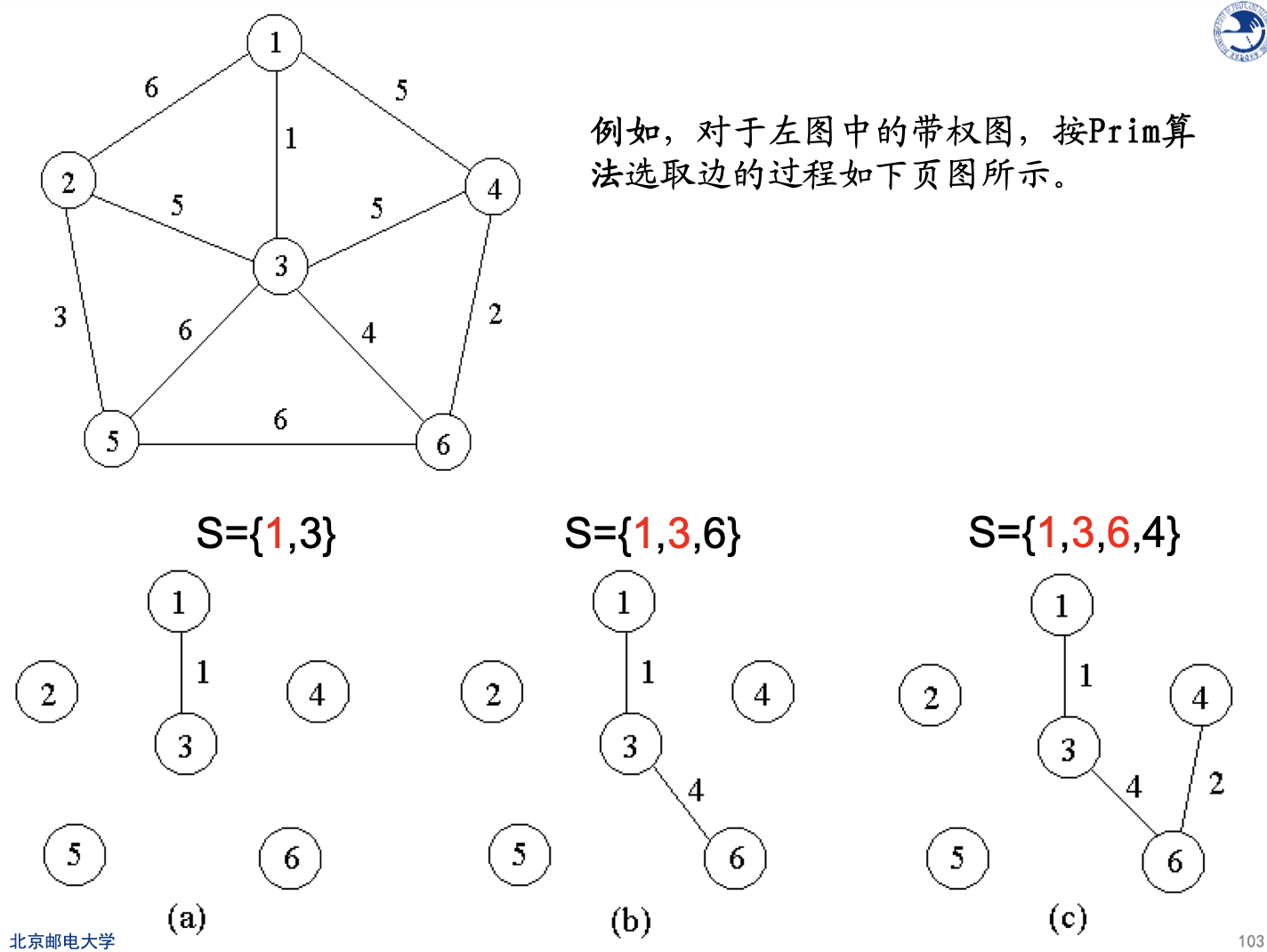
设G=(V, E)是连通带权图,V={1,2,…,n}。
Prim算法的基本原理:
-
首先置顶点集合S={1}
-
当S是V的真子集时,作如下的贪心选择:
选取满足条件i∈S,j∈V−S,且c[i][j]最小的边<i, j>,将顶点j添加到S中,边<i, j>加到边集T中。
-
重复上述过程,直到S=V为止,此时边集T就是最小生成树
在这个过程中选取到的所有边恰好构成G的一棵最小生成树。
算法复杂性:O(n2)
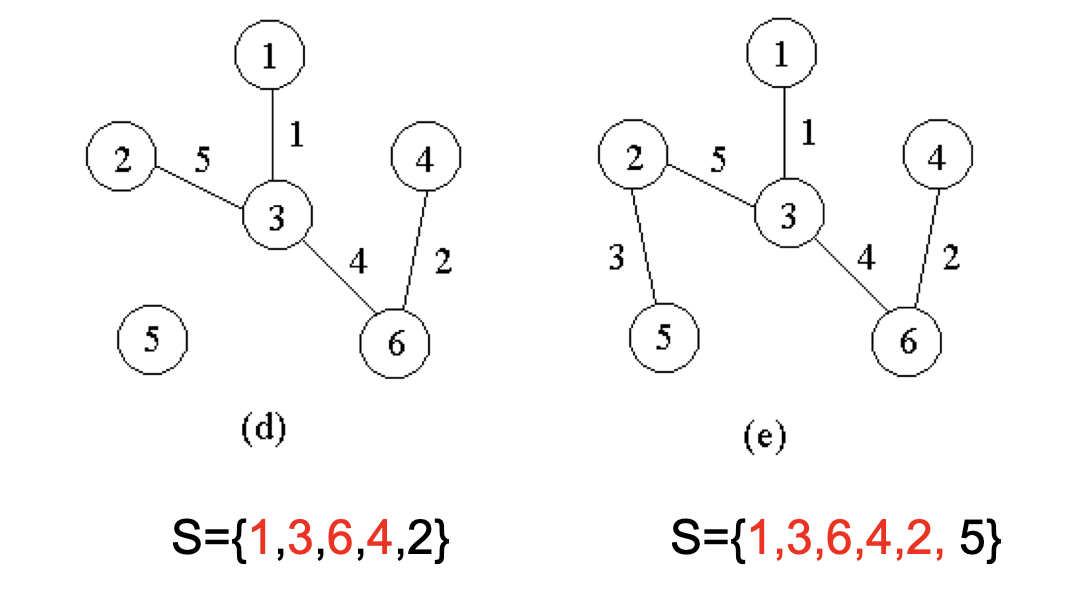
利用最小生成树性质和数学归纳法(对顶点集合S归纳)容易证明,上述算法中的边集合T始终包含G的某棵最小生成树中的边,满足贪心选择性质、最优子结构性质
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| #define INF 99999
using namespace std;
void initMap(vector<vector<int>> &map) {
for (int i = 0; i < map.size(); i++) {
map[i][i] = 0;
}
}
int prim(vector<vector<int>> &map) {
vector<int> lowCost(map[0]);
int result = 0;
for (int i = 1; i < map.size(); i++) {
int minLength = INF;
int minNode = -1;
for (int j = 0; j < map.size(); j++) {
if (lowCost[j] < minLength && lowCost[j] != 0) {
minLength = lowCost[j];
minNode = j;
}
}
lowCost[minNode] = 0;
result += minLength;
for (int j = 0; j < map.size(); j++) {
if (map[minNode][j] < lowCost[j] && lowCost[j] != 0) {
lowCost[j] = map[minNode][j];
}
}
}
return result;
}
|
该算法为最简单的版本,与Dijkstra算法类似,需要两层循环完成最短边的选择,故时间复杂度为O(n2)
查阅资料可知,还可以使用堆的方式代替邻接矩阵,实现运行时间上的优化,优化版的Prim算法可以实现时间复杂度降为O(ElogV);最优化版本的Prim算法为O(E+VlogV)
而空间复杂度方面,同样用到了邻接矩阵作为存储变量,故需要O(n2)的空间复杂度
如果要保存最小生成树的结构,需要另外开一个数组记录
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| struct Edge {
int src, dest, weight;
Edge(int s, int d, int w) : src(s), dest(d), weight(w) {}
bool operator<(const Edge &other) const {
return weight < other.weight;
}
};
int prim(vector<vector<int>> &map, vector<Edge> &minSpanningTree) {
int result = 0;
vector<int> lowCost(map[0]);
for (int i = 1; i < map.size(); i++) {
int minLength = INF;
int minNode = -1;
for (int j = 0; j < map.size(); j++) {
if (lowCost[j] < minLength && lowCost[j] != 0) {
minLength = lowCost[j];
minNode = j;
}
}
lowCost[minNode] = 0;
if (minNode != -1) {
minSpanningTree.emplace_back(Edge(minNode, i, minLength));
result += minLength;
for (int j = 0; j < map.size(); j++) {
if (map[minNode][j] < lowCost[j] && lowCost[j] != 0) {
lowCost[j] = map[minNode][j];
}
}
}
}
return result;
}
|
最小生成树之Kruskal算法
- 将G的n个顶点看成n个孤立的连通分支
- 将所有的边按权从小到大排序
- 从权最小的第一条边开始,依边权递增的顺序查看每一条边<v,w>,并按下述方法连接2个不同的连通分支:
当查看到第k条边(v,w)时,
- 如果端点v和w分别是当前2个不同的连通分支T1和T2中 的顶点时,用边(v,w)将T1和T2合并成一个连通分支,然后继续查看后续第k+1条边
- 如果端点v和w已经属于当前的同一个连通分支中,不允许将(v,w)加入,否则会产生回路。 此时,直接再查看后续第k+1条边
- 持续上述过程,直到只剩下一个连通分支——最小生成树
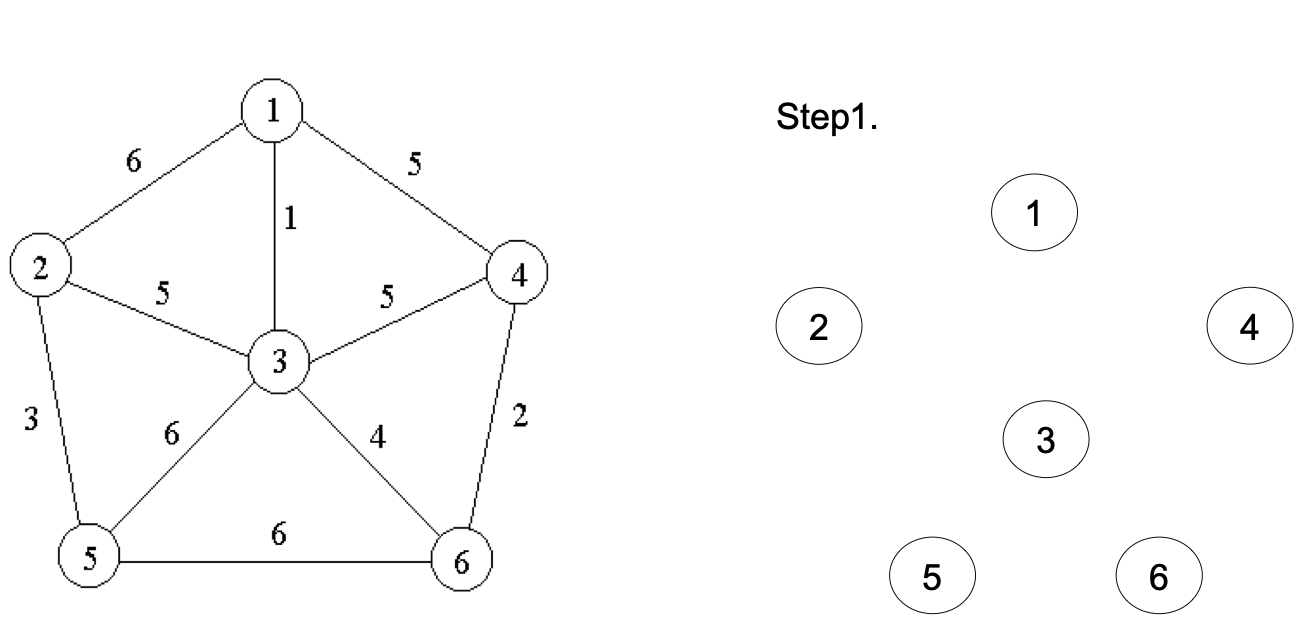
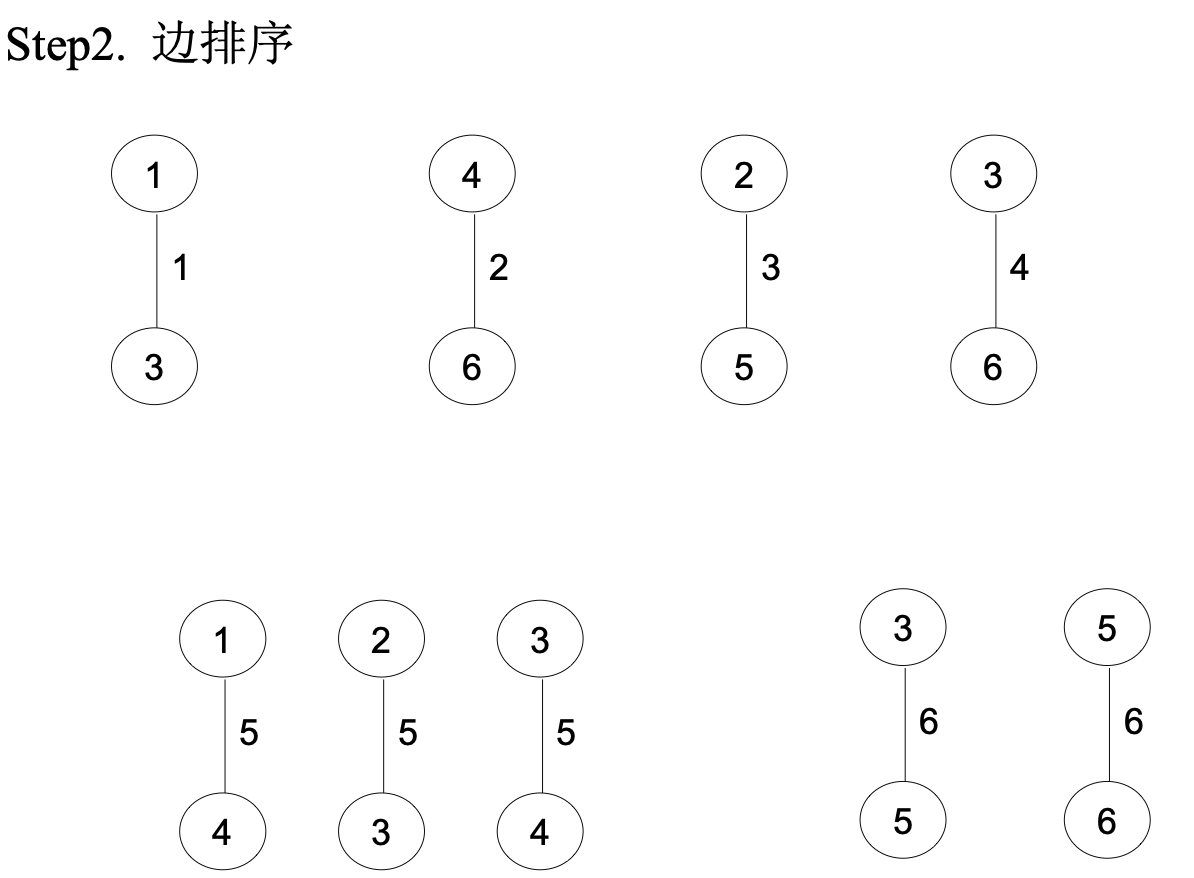
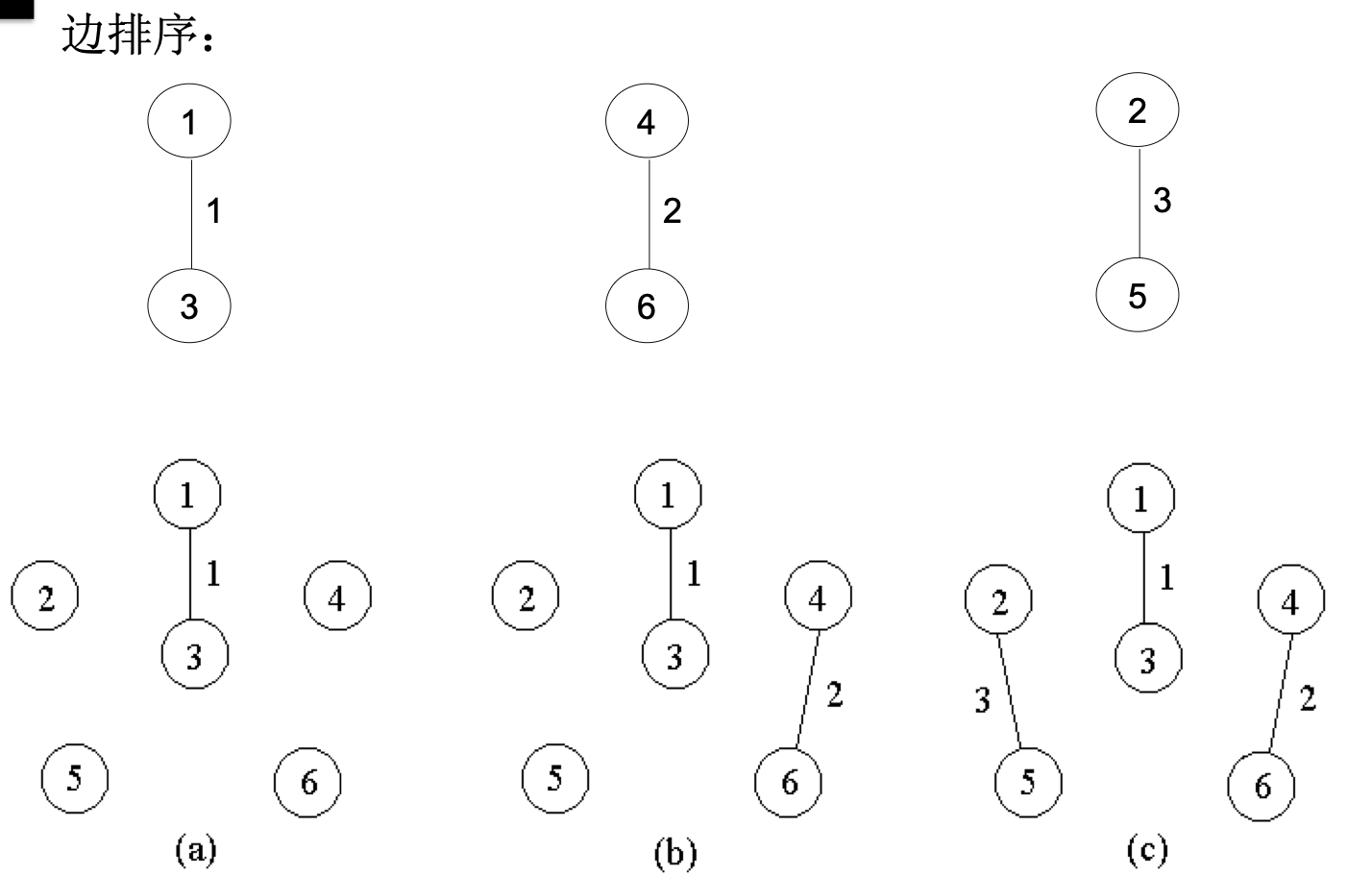
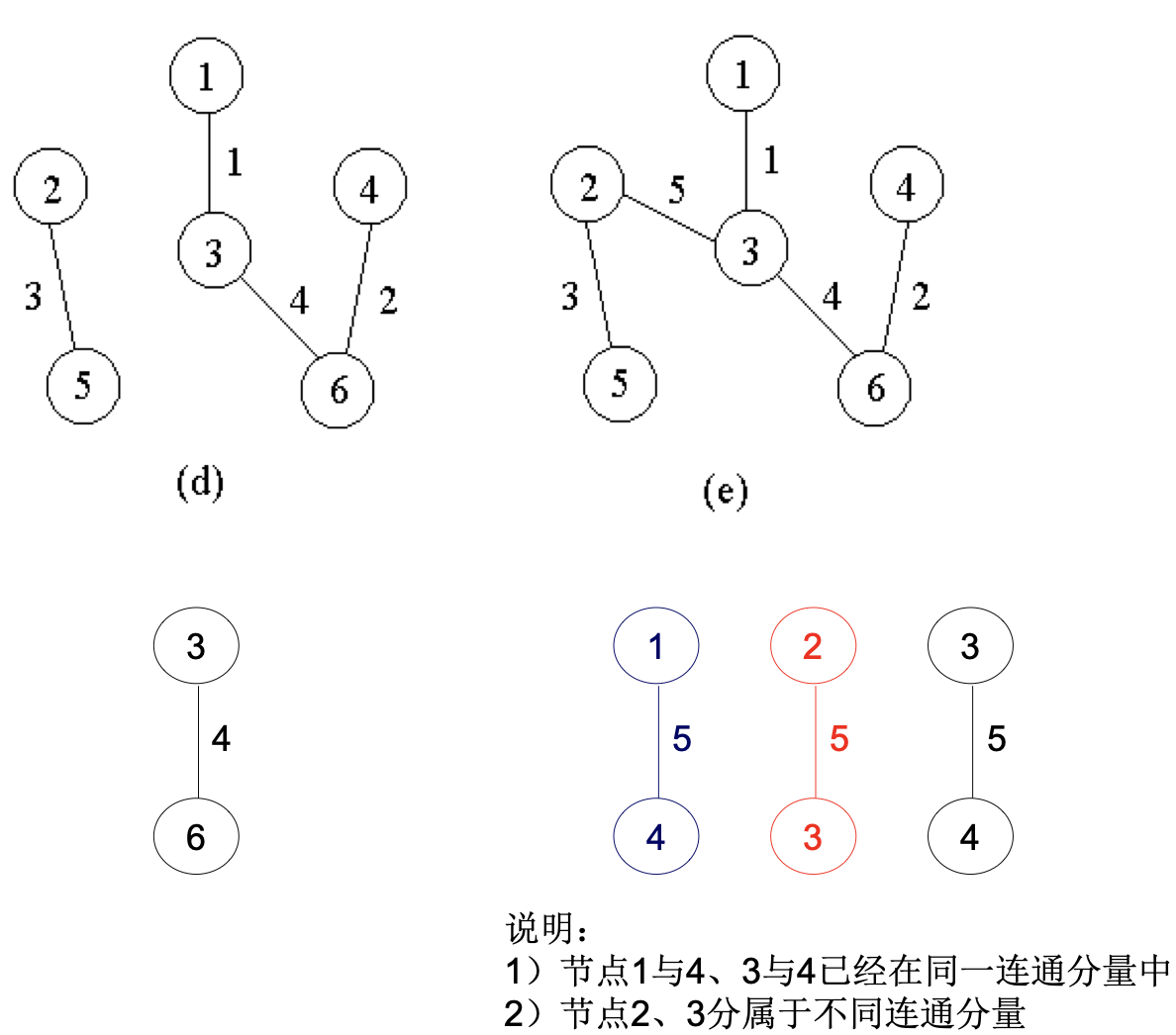
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| #define INF 99999
struct Edge {
int startNode;
int endNode;
int weight;
Edge(int startNode, int endNode, int weight) : startNode(startNode), endNode(endNode), weight(weight) {}
};
void initMap(vector<vector<int>> &map) {
for (int i = 0; i < map.size(); i++) {
map[i][i] = 0;
}
}
int kruskal(vector<vector<int>> &map, vector<Edge *> &edgeList) {
int result = 0;
sort(edgeList.begin(), edgeList.end(), [](Edge *edge1, Edge *edge2) -> bool {
return edge1->weight < edge2->weight;
});
vector<int> endList(map.size());
for (int i = 0; i < map.size(); i++) {
endList[i] = i;
}
for (auto edge: edgeList) {
if (endList[edge->startNode] != endList[edge->endNode]) {
int start = endList[edge->startNode];
for (int & item : endList) {
if(item == start) {
item = endList[edge->endNode];
}
}
result += edge->weight;
}
}
return result;
}
|
这里实际上使用了并查集的思想,设置连通分量的每一个顶点的终顶点相同,以此判断他们在同一个连通分量中
该算法只需要对大小为E的边列表进行循环,且排序算法可以使用sort实现O(logE)的时间复杂度,故总体时间复杂度为O(ElogE)
而空间复杂度方面,同样用到了邻接矩阵作为存储变量,故需要O(n2)的空间复杂度
与Prim算法比较
- 当 e =$ \Omega(n^2 )$ 时,Kruskal算法比Prim算法差
- 当 e =$ o(n^2 )$ 时,Kruskal算法比Prim算法好得多
Prim算法和Kruskal算法,从两个不同的角度:顶点和边分别入手问题,所以虽然最终都能解决问题,但很明显Prim算法更加适用于顶点稀少的图,而Kruskal算法更加适用于顶点较多、边数较少的图