
计算机系统结构 向量处理机 & 多处理机
第五章 向量处理机
典型的机器是CRAY-1,能够进行高性能运算,能够充分发挥流水线的效率,实现高性能计算。
是SIMD
向量处理方式
对以下式子进行运算:
横向处理方式
每一行从左到右进行运算,逐个求di
循环N次以下计算

发生数据冲突N次,功能切换2N次
不适用于向量处理机并行处理
纵向处理方式
每一列从上到下进行运算,即先算完全部括号内内容,再计算加法
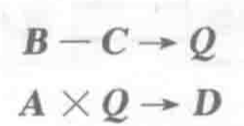
发生数据冲突1次,功能切换1次
纵横处理方式(分组处理方式)
- N:向量长度
- s:分组数
- n:每组计算的长度
- r:余数
所以一共要计算s+1组
- 每组发生数据冲突1次,总共发生数据冲突s+1次
- 每组功能切换2次,总共切换2s+1次
向量处理机的结构
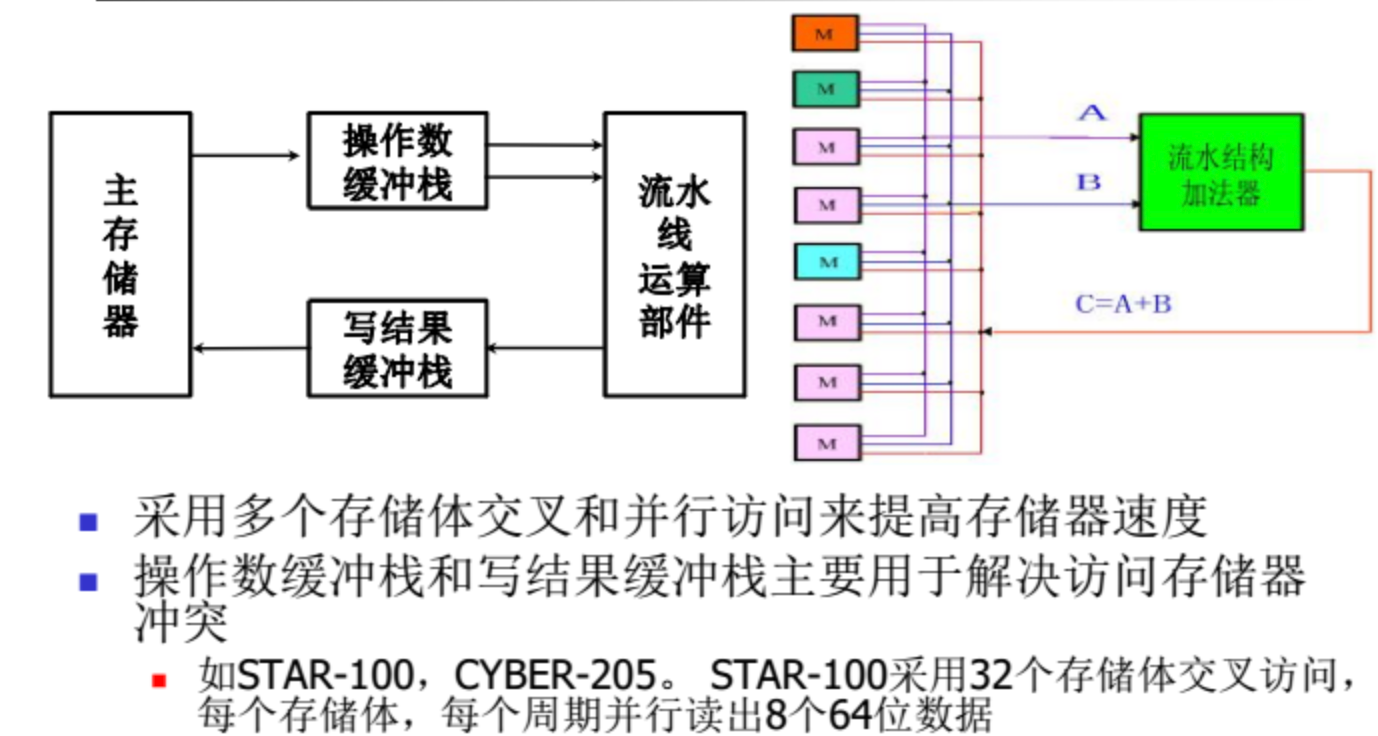
存储器-存储器结构(Memory-Memory)
对向量长度无限制,数据从存储器读两条进入缓冲栈,进入运算部件运算后写回结果缓冲栈,直接写回主存储器。
运算的中间结果不能放在寄存器中,而是写回存储器中。
适用于纵向处理方式

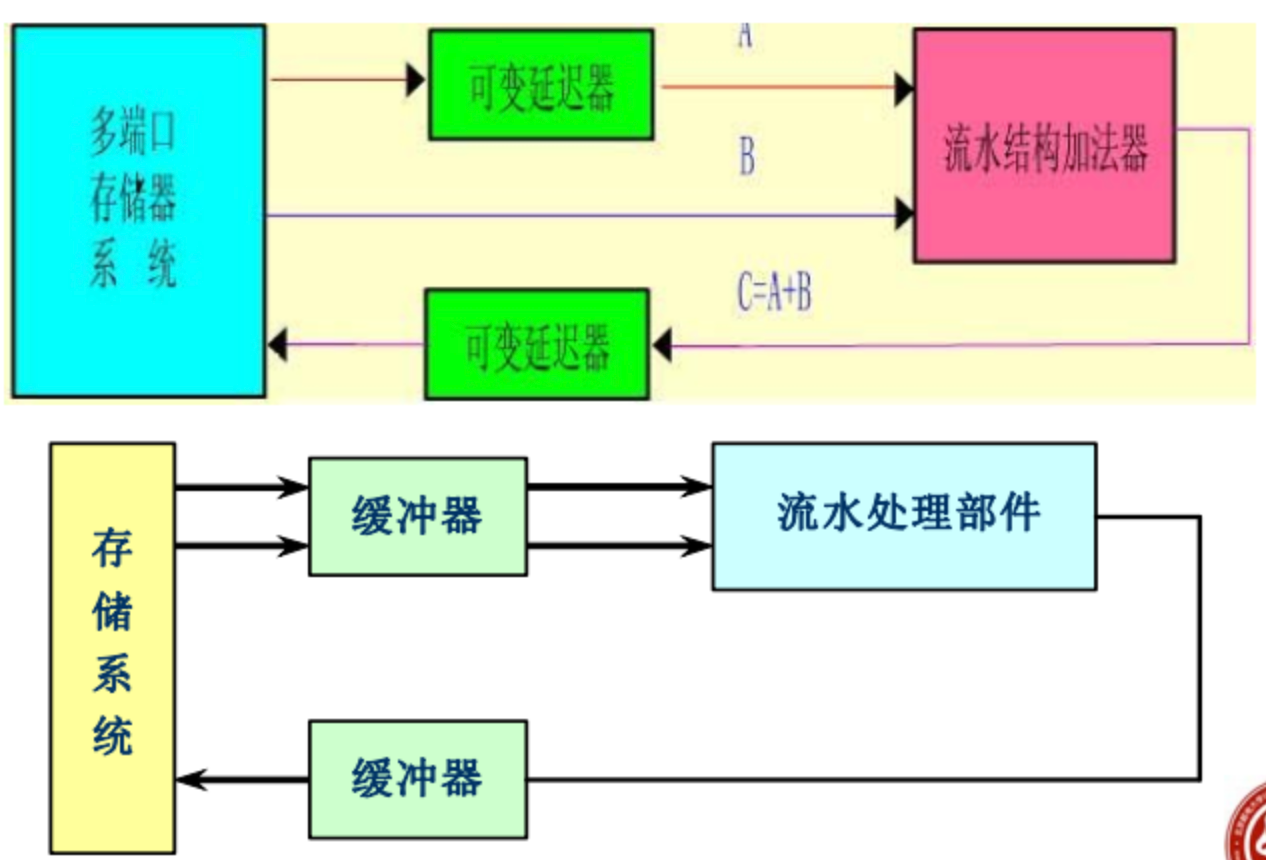

寄存器-寄存器结构(Register-Register)
在向量的分组处理方式中,向量被分为每n个数据一组。以组为单位进行数据的存取和运算。虽然这种方式对向量长度N没有限制,但组的长度n却是固定不变的,所以可以设置能快速访问的向量寄存器,用于存放源向量、目的向量及中间结果。让运算部件的输入、输出端都与向量寄存器相连。
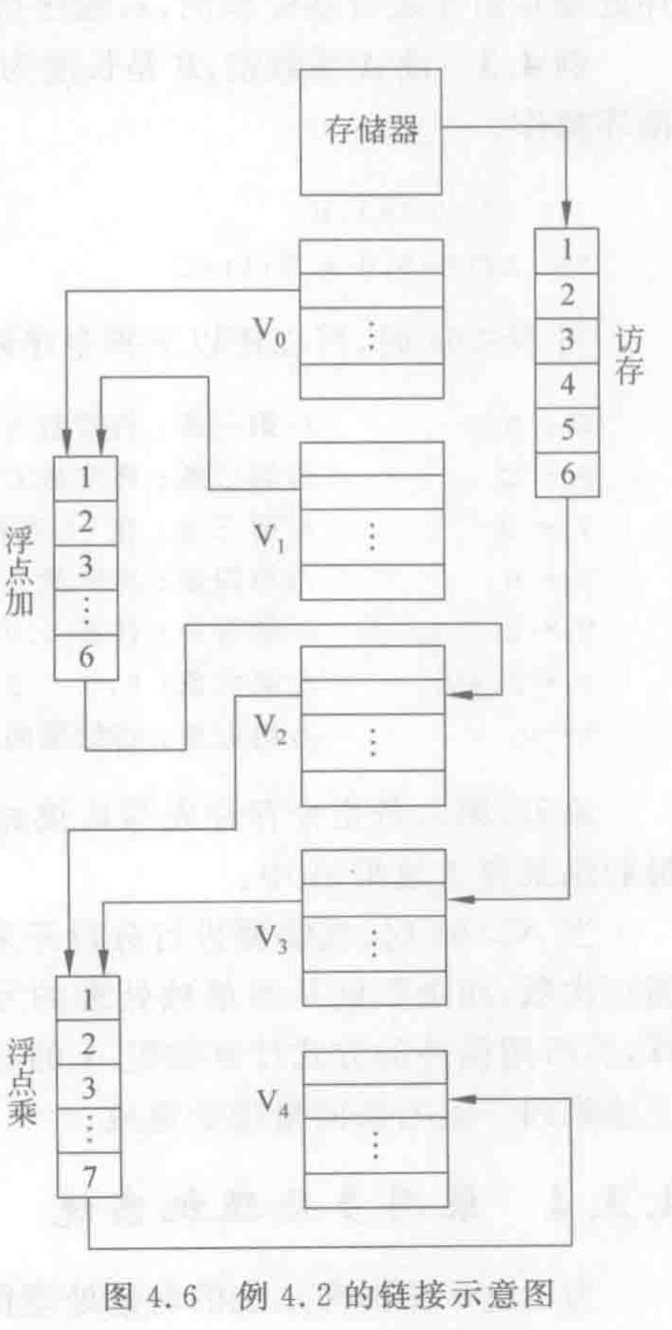
为了能充分发挥向量寄存器和可并行工作的6个流水线功能部件的作用,加快对向量的处理,Cray-1中的每个向量寄存器Vi都有连到6个向量功能部件的单独总线,而每个向量功能部件也都有把运算结果送回向量寄存器组的总线。这样,只要不出现Vi冲突和功能部件冲突,各Vi之间和各功能部件之间就能并行工作,大大加快了向量指令的处理,这是Cray-1向量处理的一个显著特点。
Vi冲突是指并行工作的各向量指令的源向量或结果向量使用了相同的Vi。

所谓功能部件冲突是指并行工作的各向量指令要使用同一个功能部件(类似于结构冲突)。
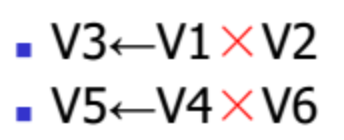
操作
- 标量与向量运算
- 向量与向量运算
- 寄存器写入主存储器(写)
- 主存储器写入寄存器(读)
提高向量处理机性能的常用技术
设置多个功能部件
使各个功能部件可以并行工作
采用链接技术
把流水线定向的思想引入到向量计算中
- 指令发生RAW冲突(先写后读冲突)
- 没有发生功能部件冲突
- 源向量寄存器没有冲突
LDV V3, M(A)
ADDV V2, V1, V0
MULV V4, V2, V3
第1、2条指令无向量寄存器使用冲突,也无功能部件使用
冲突,因而可以并行执行
第3条指令与第1、2条指令均存在先写后读相关,因而可
将第3条指令与第1、2条指令链接执行
-
要进行链接的向量指令的向量长度必须相等
-
只有在前一条指令的第一个结果元素送人结果向量存器的那一个时钟周期才可以进行链接。如果错过这个时刻,就无法进行链接了,这时只好按串行方式执行这两条指令。
就是说不能算到中间突然一转链接技术,只能从头就开始使用
-
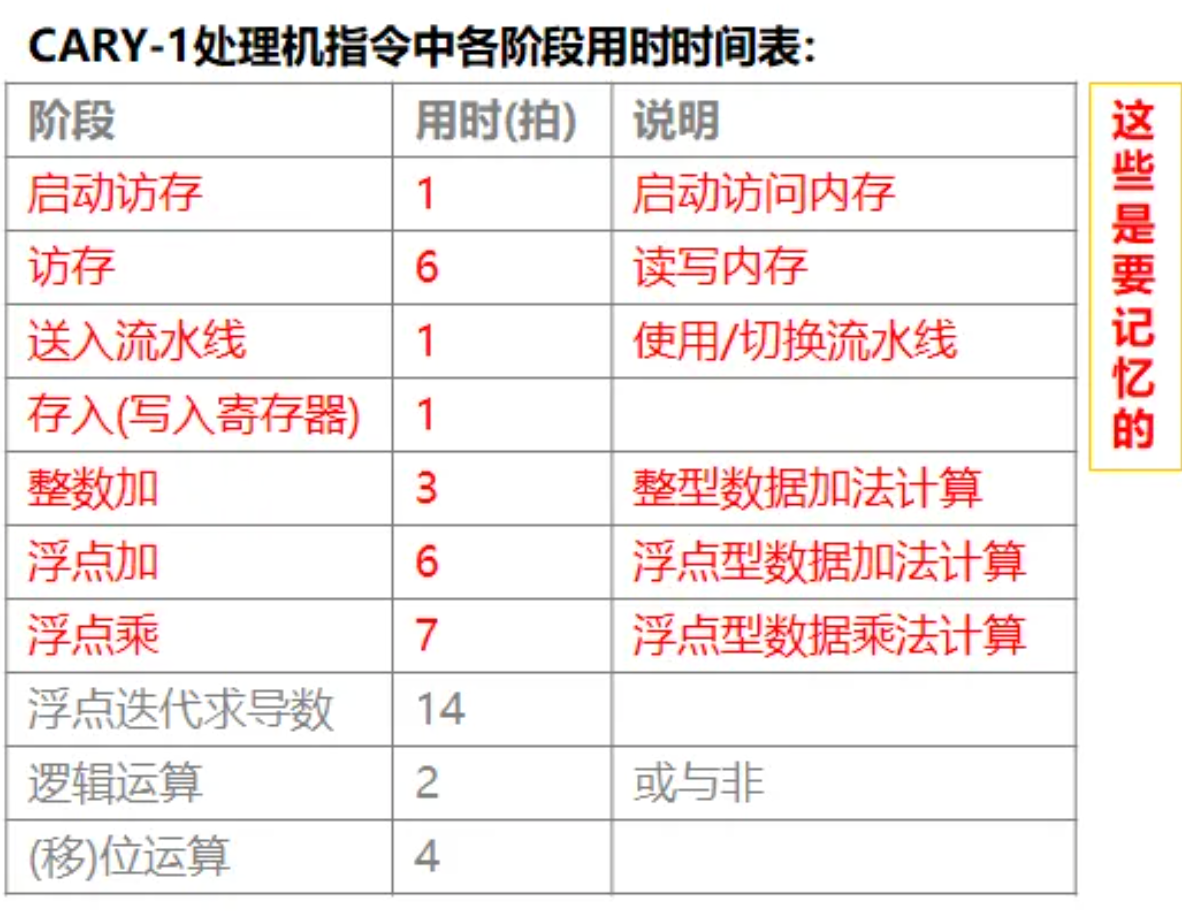
当一条向量指令的两个源操作数分别来自前面紧邻的两条指令的结果时,要求这两条指令产生运算结果的时间必须相等,即要求有关功能部件的通过时间相等。例如,上述例子中的访存和浮加功能部件的通过时间都是6拍。
由于同步的要求,链接时,Cray-1中把向量数据元素送石住向量功能部件以及把结果存入向量寄存器都需要一拍时间,从存储器中把数据送入访存功能部件也需要一拍时间。


第三种采用链接方式,第一、二条并行运行,第三条与前两条链接
 $$
T = (1+6+1)+(1+7+1)+N-1 = 16+N
$$
可以理解为第一段流水线后直接拼上第二段流水线,因此N-1只加了1次
$$
T = (1+6+1)+(1+7+1)+N-1 = 16+N
$$
可以理解为第一段流水线后直接拼上第二段流水线,因此N-1只加了1次
采用分段开采技术
加快循环的处理
当向量的长度大于向量寄存器的长度(64)时,必须把长向量分成长度固定的段,然后循环分段处理,每一次循环只处理一个向量段。
这种技术称为分段开采技术-由系统硬件和软件控制完成,对程序员是透明的。
采用多处理机系统
包含多个向量处理机
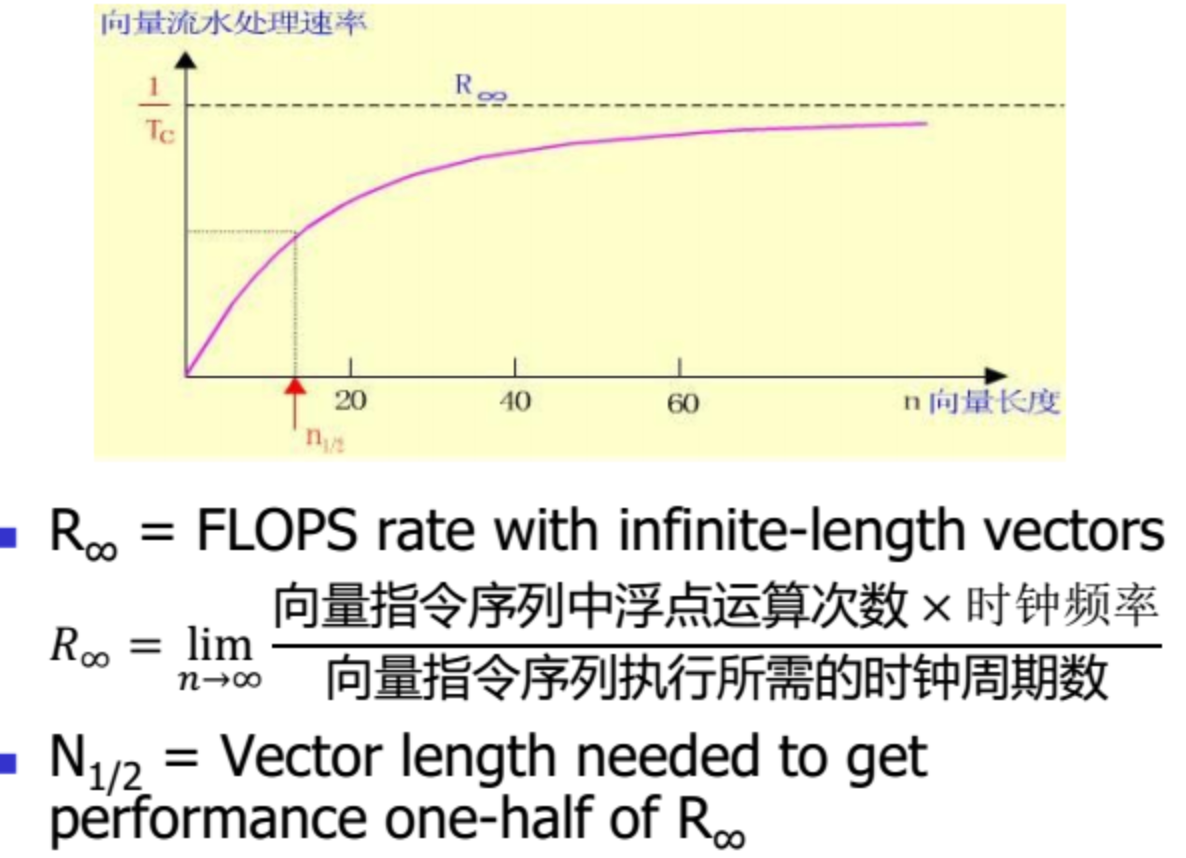
向量机的性能指标

编队
在同一个时钟周期内可一起开始执行的几条向量指令
同一个编队中的指令一定不存在功能部件冲突和数据相关



阵列处理机
-
SIMD
-
使用资源重复
在系统中设置多个相同的处理单元来开发并行性,利用并行性中的同时性,所有处理单元必须同时进行相同操作;
-
阵列机是以某一类算法为背景的专用计算机。由于阵列机中通常都采用简单、规整的互连网络来实现处理单元间的连接操作,从而限定了它所适用的求解算法类别。
-
阵列机的研究必须与并行算法的研究密切结合;
-
由于PE结构相同,属于同构型并行机。控制器实质上是一个标量处理机,而为了完成I/O操作以及操作系统的管理,尚需一个前端机,因此实际的阵列机系统是一个异构型多处理机系统。
第六章 多处理机
是MIMD
多处理机结构
根据存储器的组织结构,分为以下两类多处理机
集中式共享存储器结构
共享一个集中的物理存储器
也被称为对称式共享存储器多处理机(SMP,UMA)

分布式存储器多处理机
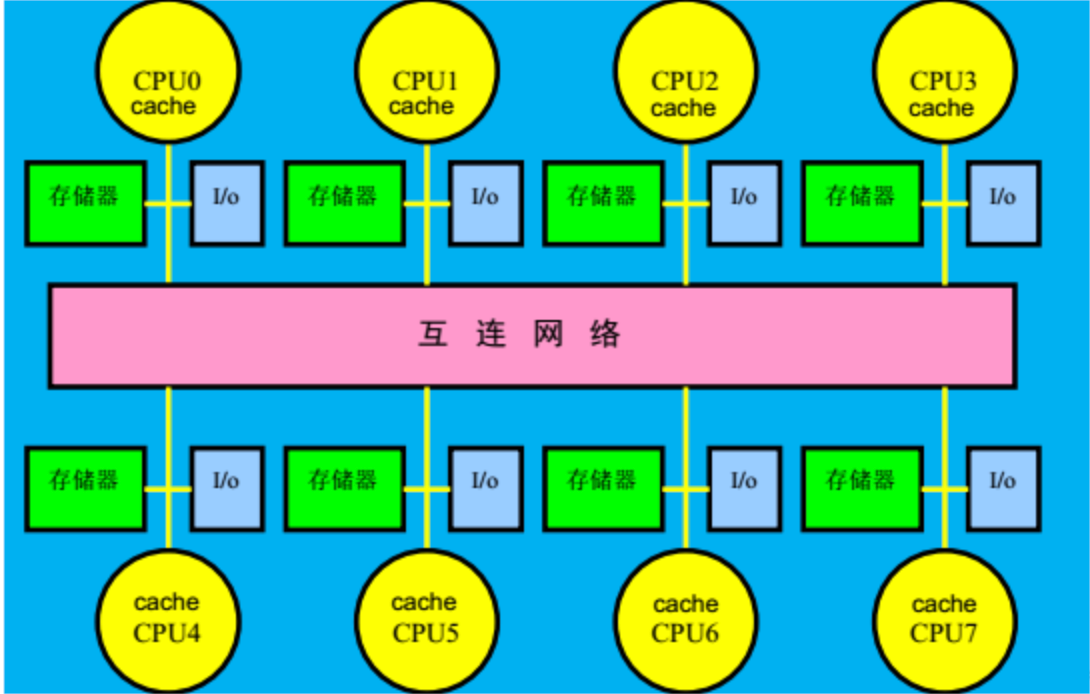
- 存储器物理上是分布的
- 每个结点都包含处理器、存储器、I/O,互连网络接口
将存储器分布到各结点的两个优点
- 如果大多数的访问是针对本结点的局部存储器,则可降低对存储器和互连网络的带宽要求;
- 对本地存储器的访问延迟时间小。
最主要的缺点
处理器之间的通信较为复杂,且各处理器之间访
问延迟较大。
存储器的系统结构
共享地址空间
物理上分离的所有存储器作为一个统一的共享逻辑空间进行编址。
任何一个处理器可以访问该共享空间中的任何一个单元(如果它具有访问权),而且不同处理器上的同一个物理地址指向的是同一个存储单元。
这类计算机被称为分布式共享存储器系统(DSM - Distributed Shared-Memory),NUMA(NUMA - Non-Uniform Memory Access)
分离地址空间
把每个结点中的存储器编址为一个独立的地址空间,不同结点中的地址空间之间是相互独立的
整个系统的地址空间由多个独立的地址空间构成
每个结点中的存储器只能由本地的处理器进行访问,远程的处理器不能直接对其进行访问。
每一个处理器-存储器模块实际上是一台单独的计算机
现在的这种机器多以集群的形式存在
两种通信机制
消息传递通信机制
- 多个独立地址空间的计算机采用
- 通过处理器间显式地传递消息来完成
- 消息传递多处理机中,处理器之间是通过发送消息来进行通信的,这些消息请求进行某些操作或者传送数据。
主要优点
-
硬件较简单。
-
通信是显式的,因此更容易搞清楚何时发生通信以及通信开销是多少。
-
显式通信可以让编程者重点注意并行计算的主要通信开销,使之有可能开发出结构更好、性能更高的并行程序。
-
同步很自然地与发送消息相关联,能减少不当的同步带来错误的可能性。
但是,在消息传递的硬件上支持共享存储器就困难得多。所有对共享存储器的访问均要求操作系统提供地址转换和存储保护功能,即将存储器访问转换为消息的发送和接收。
同步消息传递
异步消息传递
共享存储器通信机制
- 共享地址空间的计算机系统采用
- 处理器之间是通过用load和store指令对相同存储器地址进行读/写操作来实现的。
主要优点
- 与常用的对称式多处理机使用的通信机制兼容。易于编程,同时在简化编译器设计方面也占有优势。
- 采用大家所熟悉的共享存储器模型开发应用程序,而把重点放到解决对性能影响较大的数据访问上。
- 当通信数据量较小时,通信开销较低,带宽利用较好。
- 可以通过采用Cache技术来减少远程通信的频度,减少了通信延迟以及对共享数据的访问冲突。
- 在共享存储器上支持消息传递相对简单
于是这个分类如下:
集中式共享存储器结构
分布式存储器结构 - 共享地址空间 - 共享存储器通信机制
分布式存储器结构 - 分离地址空间 - 消息传递通信机制
并行处理面临的挑战
两个重要的挑战
- 程序中的并行性有限
- 相对较大的通信开销
对称式共享存储器
多个处理器共享一个存储器
提供共享cache和私有cache
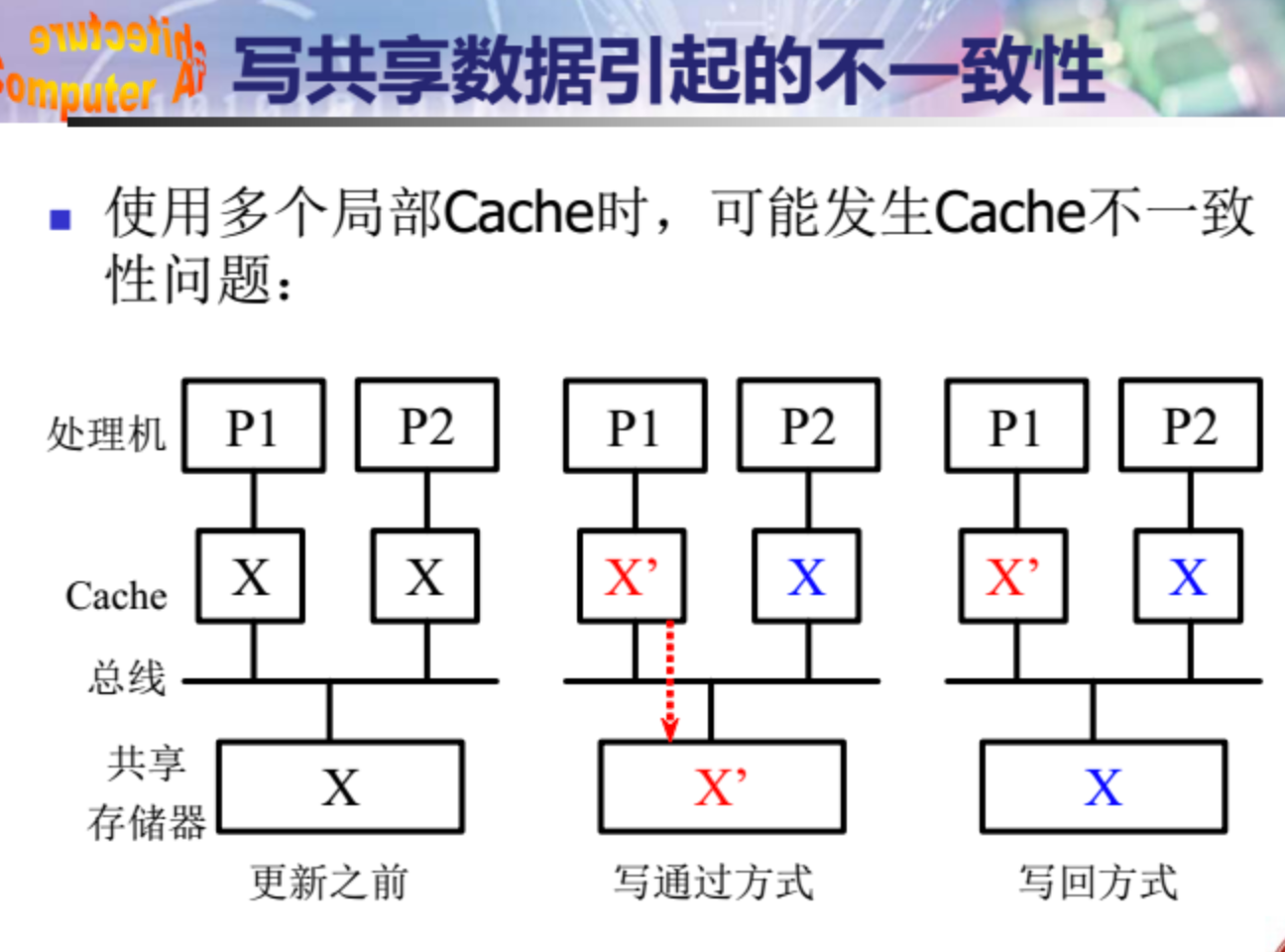
Cache一致性问题
允许共享数据进入Cache,就可能出现多个处理器的Cache中都有同一存储块的副本,
当其中某个处理器对其Cache中的数据进行修改后,就会使得其Cache中的数据与其他Cache中的数据不一致。
出现不一致性问题的原因举例:
- 共享可写的数据
- 进程迁移
- I/O传输
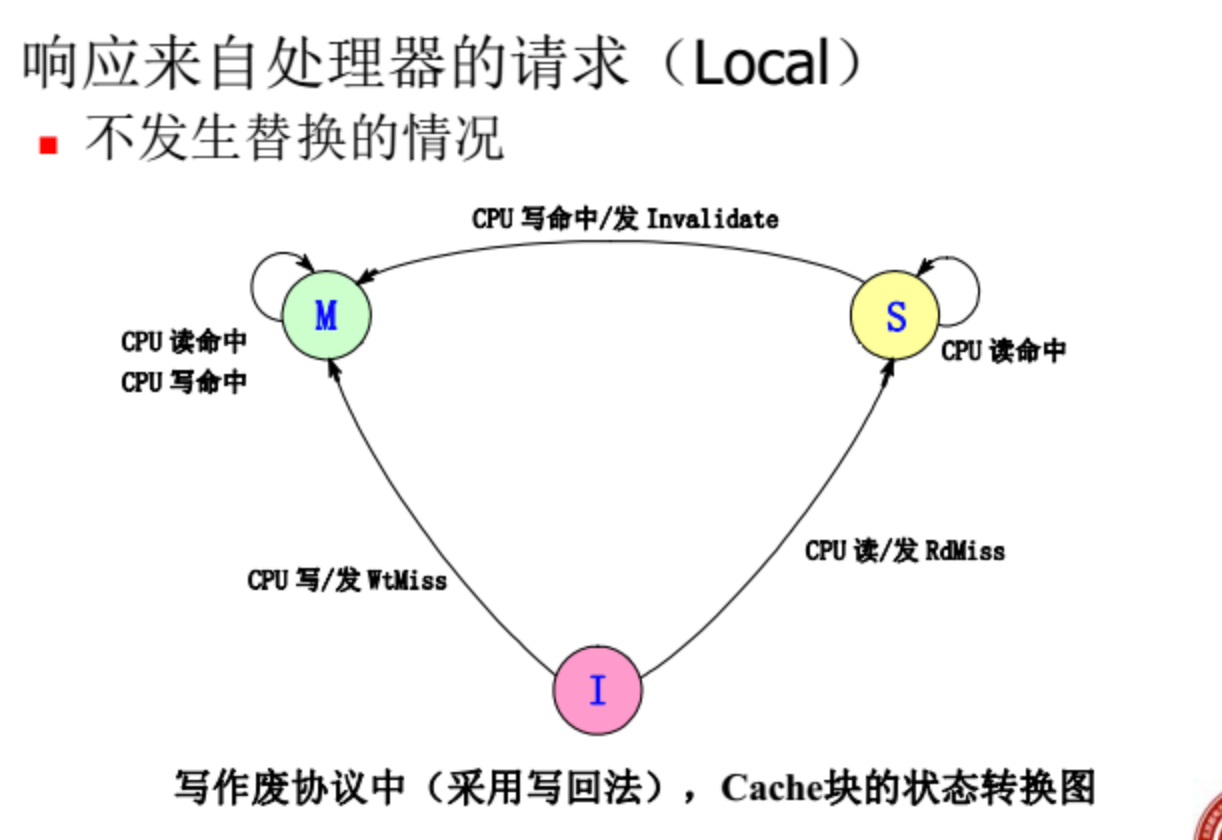
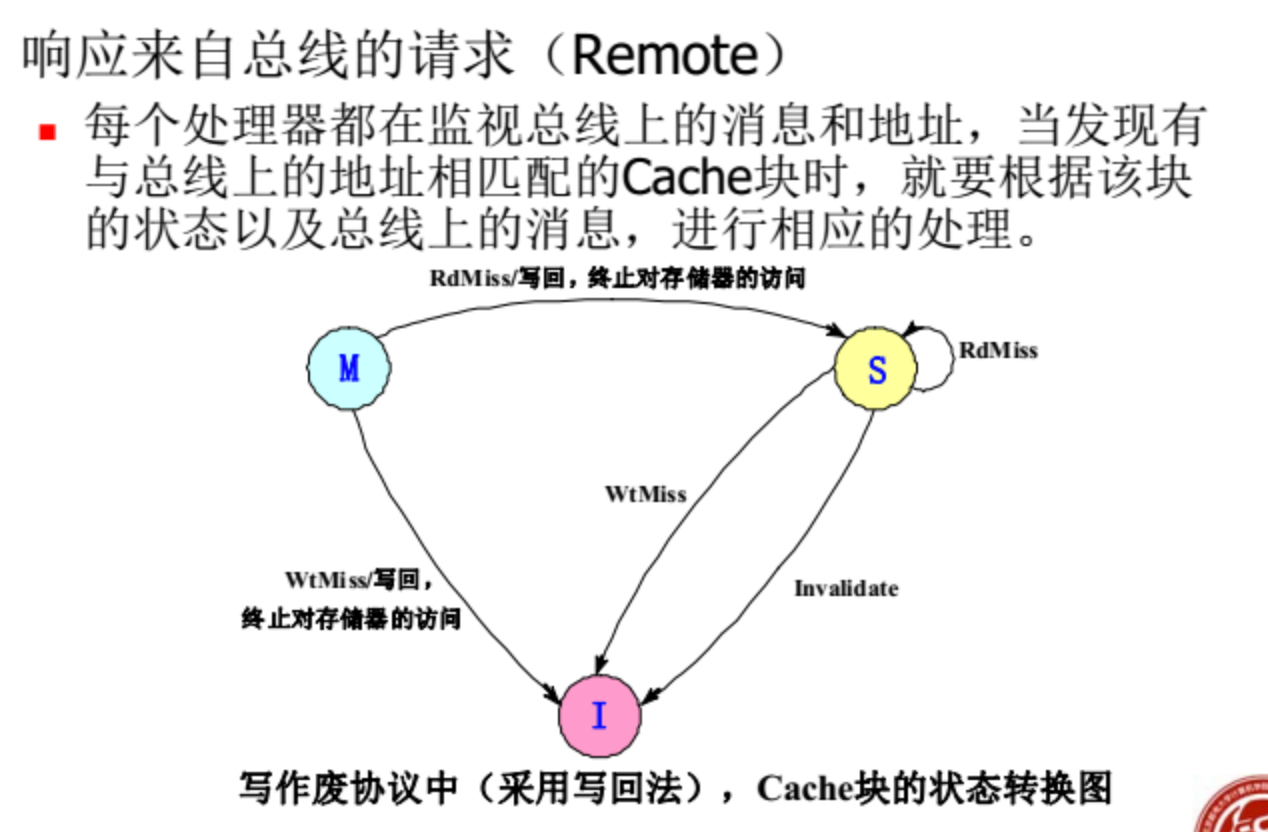
监听协议
前提:有总线,所以适用于共享存储器

- M:本地cache发生调整,是全局唯一一份,未写入存储器
- S:共享状态,多个处理器中有副本
- I:cache中该块内容无效

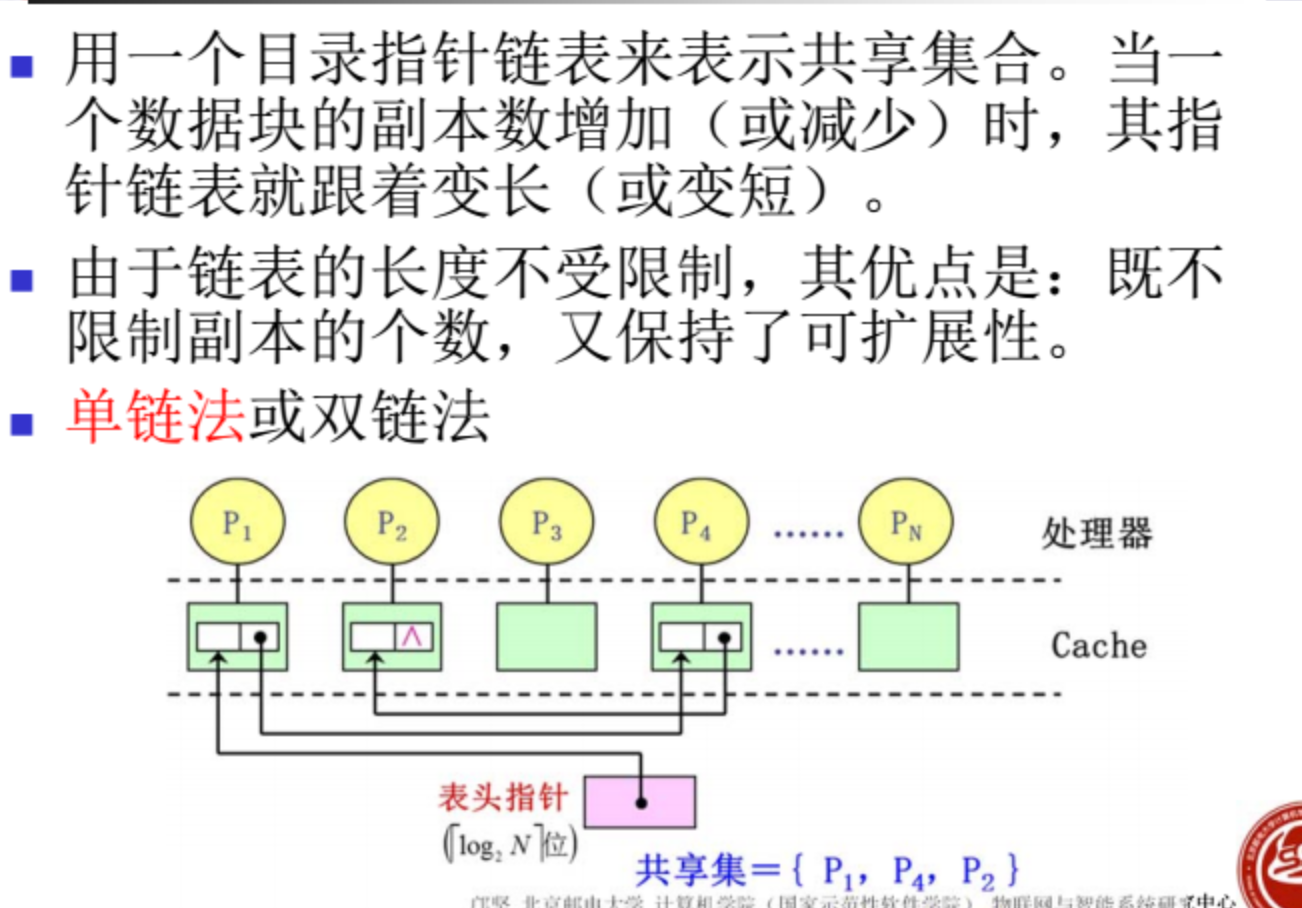
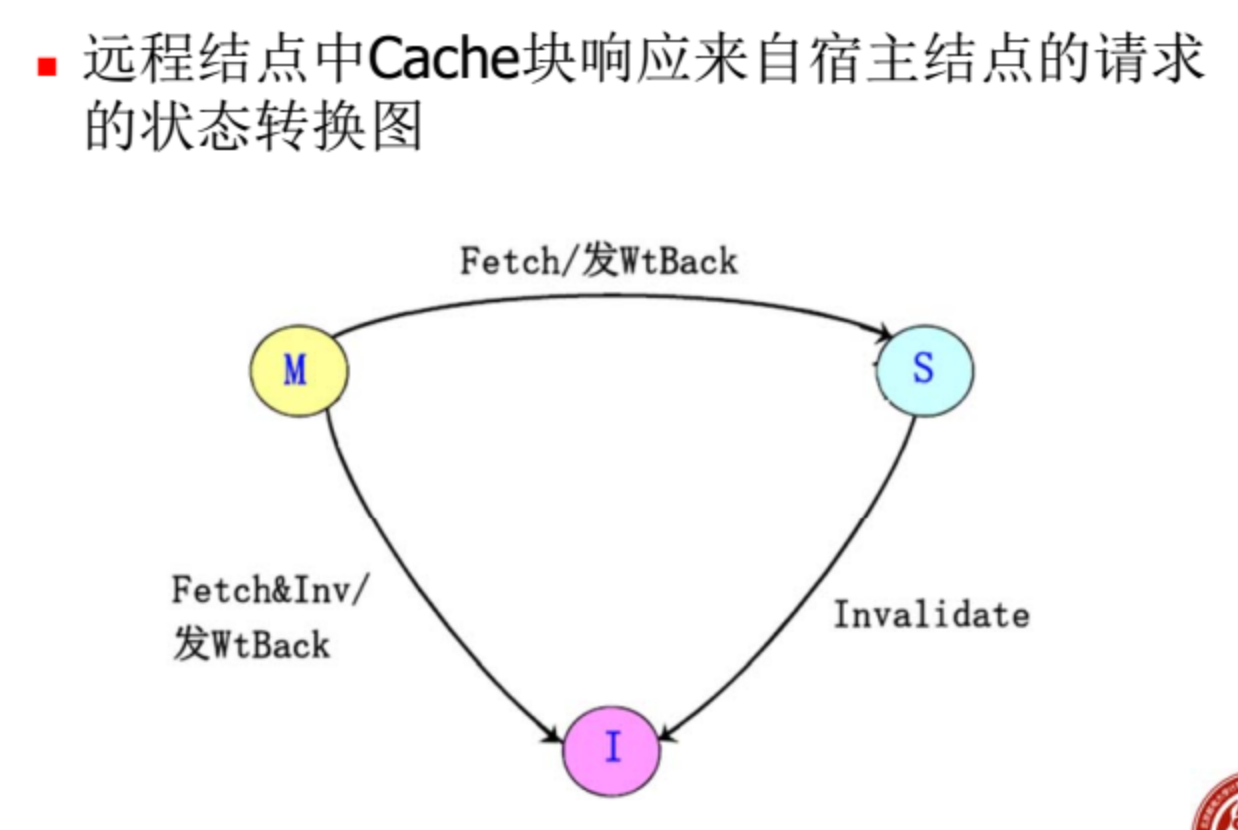
目录表协议
在非总线结构的多处理机系统中,采用基于目录的Cache一致性协议
目录:一种集中的数据结构。对于存储器中的每一个可以调入Cache的数据块,在目录中设置一条目录项,用于记录该块的状态以及哪些Cache中有副本等相关信息。
-
全映像 一个向量每位记录每个处理机是否有副本
-
有限映像

-
链式映像目录
-
未缓冲:该块尚未被调入Cache。所有处理的Cache中都没有这个块的副本。
-
共享:该块在一个或多个处理机上有这个块的副本,且这些副本与存储器中的该块相同。
-
独占:仅有一个处理机有这个块的副本,且该处理机已经对其进行了写操作,所以其内容是最新的,而存储器中该块的数据已过时。这个处理机称为该块的拥有者。


实现多线程的方法
细粒度:每句指令之间都进行线程的切换,以时间片轮转实现
粗粒度:时间较长停顿时才进行线程切换
同时多线程(SMT)
- 一种在多流出、动态调度的处理器上同时开发线程级并行和指令级并行的技术。
- 开发的基础:动态调度的处理器已经具备了开发线程级并行所需的许多硬件设置。

目前流行的高性能并行计算机系统结构
目前流行的高性能并行计算机系统结构通常可以分成以下5类:
- 并行向量处理机(PVP)
- 对称式共享存储器多处理机(SMP)
- 分布式共享存储器多处理机(DSM)
- 大规模并行处理机(MPP)
- 机群计算机(Cluster)


