
数据库系统原理 期末复习(一)
第一章
绪论
数据库是用来有效管理数据的工具
文件系统从一定程度上没有屏蔽数据的逻辑存储结构,带来了前端与数据的不独立,而且会造成数据冗余,有数据不一致的可能;还有并发问题、备份问题
数据库三层结构
物理层
描述物理存储结构(物理模式)
内模式
逻辑层
描述逻辑存储结构以及之间的关系(概念模式)
视图层(View level)
面向某一类用户的逻辑信息
- 外模式可能有多个,全部综合起来构成的整体就是数据库的逻辑模式
外模式
三层模式需要在之间建立映射关系(两级Mapping),形成了数据的独立性
数据库的独立性
物理数据的独立性(完备)
面对物理数据的改变,前端操作不需要进行更改
逻辑数据独立性(不完备)
逻辑方式的改变,前端应用不一定需要进行更改
只需要改视图与逻辑模式之间的映射(映像)
如果说**模式(Schema)是数据的结构,那么实例(Instance)**就是某一个时候数据库包含的内容
实例是相对来说比较动态的
数据模型
数据结构
- 基于对象的模型
- 实体关系模型
- 面向对象模型
- 基于记录的模型
- 层次数据模型
- 网状数据模型
- 关系数据模型
数据库语言
数据定义语言(Data Definition Language,DDL)
数据操作语言(Data Manipulation Language,DML)
query,insert,delete,update
SQL是非过程化的语言
此外,还有数据控制语言DCL(负责权限控制)
数据库三层结构图
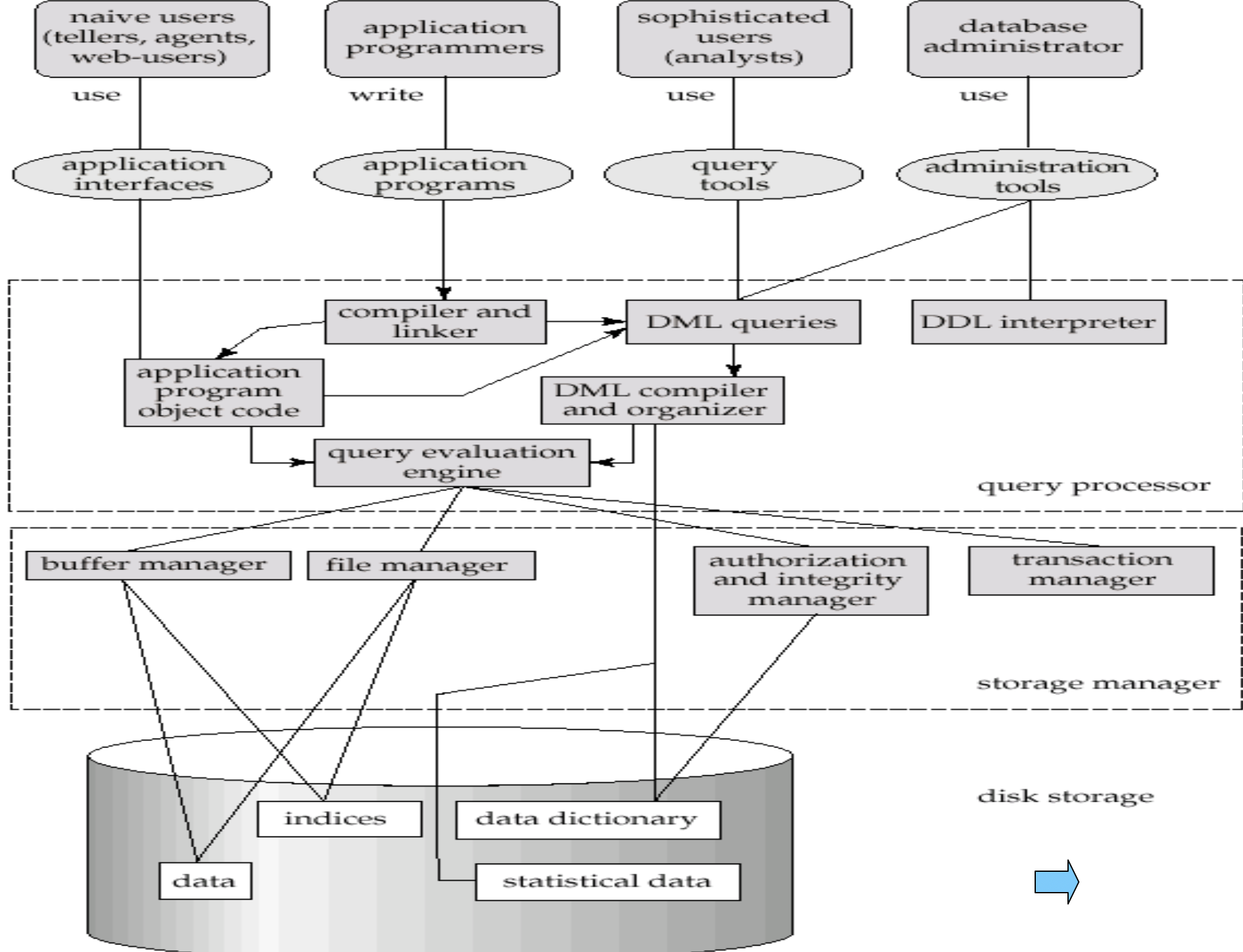
- data:数据
- indices:索引
- data dictionary:数据字典,存放的是元数据,也就是管理数据的数据(关键常驻内存)
- query processor & storage manager:DBMS
程序结构
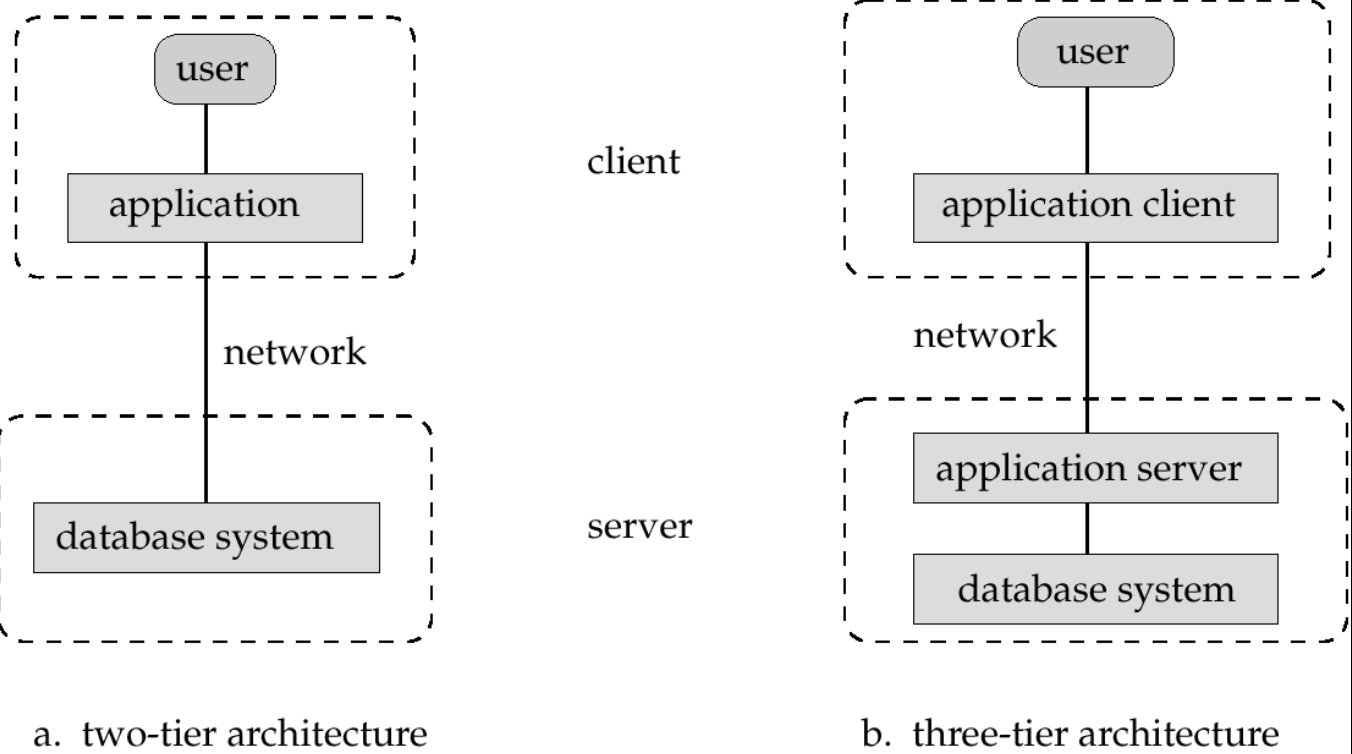
C/S:client/server结构,上图都是c/s结构
B/S:browser/server/database结构
第二章 关系模型
关系模型的数据结构
关系 relation
关系的定义:一系列域的笛卡尔积的子集
域:取值范围,数学意义上可以是无限的
要注意笛卡尔积在数学意义上不满足交换律,位置信息是有含义的
关系在数学意义上可以是无限的
注意:在数据库中,为每个域引入了一个名称(也就是属性),此时该关系满足交换律;且关系在数据库中是各个域的笛卡尔积的有限的,有意义的子集
模式 relation schema
实例 relation instance
可以用二维表来表示建立在一个关系上的关系实例
-
表头即为属性
-
一行即为一条记录
-
行的顺序不需要严格要求(可以乱序)
-
列的顺序也不需要严格要求,因为关系满足交换律
-
属性都是原子的(atomic),不再可分 (关系数据库的第一范式)
-
属性名在同一张表中不能重复
User.Database.Table.Attribute
-
行不能重复(实际应用中可以选择重复)
-
不同的属性可来自相同取值域
关系模型的概念
空值 NULL
在数据库中代表两个情况:
- 数据不存在
- 还没有查到数据
超键 SuperKey
R(U) is a relation schema , K ⊆ U;
K is a superkey(超键)for R:
for any r, no two distinct tuples have the same values on K. That is ,if t1 and t2 are in r and t1≠t2, then t1[k] ≠t2[k];
就是可以唯一确定元组的属性集合
候选键 CandidateKey
是可以唯一确定元组的最小超键
也就是说,去掉候选键后就无法唯一确定元组了
- 唯一性
- 最小性
主键 PrimaryKey
可能存在若干个候选键,可以选择其中一个作为主键
主键的选择一般根据前端应用需求或数据特点决定
主键的取值不能为空(NULL)
外键 ForeignKey
对两张表R1,R2,如果R1包含了R2的主键X,那么X被称为参照R2的外键
-
外键X在R1中
-
参照的是R2中的主键
-
外键的取值可以为NULL
-
外键的命名不一定需要和它参照的主键名相同,可以在系统中指定
-
外键可以定义在同一张表上,也就是参照自己这张表的主键
完整性约束 Integerty Constraint
实体完整性约束 Integrity Constraint of Primary Key
主键不能为空,即它的属性都不能为空
指的是主键的任意一列都不能为空
参照完整性约束 Referential Integrity Constraint
外键取值要么为NULL,要么一定来源于参照的主键的值
除此之外,用户也可以自定义完整性约束
关系代数 Relational Algebra
- 选择 Select
- 投影 Project
- 并 Union
- 差 Set Difference
- 笛卡尔积 Cartesian product
- 更名 Rename
真正的操作对象是表中的数据
选择 Select
一元操作,只对一张表操作,结果由满足条件的元组构成
- p is called the selection predicate(选择断言条件)
- σ_p(r) = \{t | t ∈ r \and p(t)\}
Eg.
从班级中选择出女同学
投影 Project
一元操作,只对一张表操作
A是属性
r是关系
选择出的是满足属性条件的列
关系代数中,由于关系的记录不能重复,所以当结果存在相同元组时,结果只会存在一条
而SQL提供是否需要去除重复项的功能
集合 Union
二元操作,对两张表操作
-
-
-
结果是两张表的合并
-
属性个数要一致
属性名称不必一致,因为操作对象是数据
-
域要相容
关系代数中,由于关系的记录不能重复,所以当结果存在相同元组时,结果只会存在一条
而SQL提供是否需要去除重复项的功能
差 Set
二元操作
-
-
-
属性个数要一致
属性名称不必一致,因为操作对象是数据
-
域要相容
区分不等于操作<>,不等于操作只会筛选出不等于的数据
(一个人同时选了01,02两门课,不等于01的操作还是会把这个人选择到)
而差操作可以实现选出没有选择01的人,此时上文这个人将不会被选择到
笛卡尔积 Cartesian-Product
-
-
-
任意组合,m条*n条记录,a+b个属性(名字相同也不去重)
-
无要求
更名 Rename
可以返回一个属性重命名的表达式
附加操作
交 Set-Intersection
二元操作,对两张表操作
-
-
-
结果是两张表的公共部分
-
属性个数要一致
属性名称不必一致,因为操作对象是数据
-
连接 Join
有条件的笛卡尔积
自然连接 Natural-Join
也叫内连接
-
无需自己定义条件的自然连接,自然认为条件是均有的属性
-
-
B是r和s均有的属性
除法 Division
它不讲我不学,快乐北邮每一天
赋值操作 Alignment
就是赋值
外连接 Outer Join
其实就是内连接,但是会将没有连接的行也一样放入结果中返回,没有连接上的记录值用null代替
- ⟕ 左外连接,会将左边表没有连接的行也一样放入结果中返回
- ⟖右外连接,会将右边表没有连接的行也一样放入结果中返回
- ⟗全外连接,会将左、右表没有连接的行放入结果中返回
空值 NULL
任何含有NULL的代数表达式的结果都是NULL
-
Comparisons with null values return the special truth value: unknown
-
Three-valued logic using the truth value unknown:
-
- OR: (unknown or true) = true,
(unknown or false) = *unknown
(*unknown or unknown) = unknown - AND: (true and unknown) = unknown,
(false and unknown) = false,
(unknown and unknown) = unknown - NOT*: (not* unknown) = unknown
- OR: (unknown or true) = true,
-
Result of select predicate is treated as false if it evaluates to unknown
数据库的调整操作
删除 Deletion
插入 Insertion
更新 Updating
更新表中对应属性的值

第三-四章 SQL语句
建表
1 | create table R ( |
删表
1 | drop table R |
添加属性
1 | alter table R add A TYPE |
选择
1 | select [distinct] name,id |
%:任意字符匹配
_:单个字符匹配
[]:匹配括号中的任意字符
更名
1 | select name |
排序
1 | select id |
asc:升序
desc:降序
集合操作 - 并、交、差
1 | (select id from A) |
运算操作 avg、min、max、count
1 | select avg(score) |
全部的运算操作中,只有count * 不忽略null值
分组 group by
1 | select id,avg(salary) |
注意:使用group by后,select出的只能是having的属性或运算后的属性
having子句中的运算操作在组形成之后使用,而where子句中的运算操作在组形成之前使用
子语句
1 | select name |
some all
1 | select name |
Exists
1 | select name |
如果子句的结果不为空,exists会返回true
unique
1 | select name |
如果子句的结果没有冲突,unique会返回true
with
1 | with get_salary(value) as ( |
with提供的实际上是函数的功能,对外暴露的属性放置在括号中。
删除记录 delete
1 | delete from R |
插入记录 insert
1 | insert into R |
Add all instructors to the student relation with tot_creds set to 0
1 | insert into Student |
更新记录
1 | update R |
case when
1 | update R |
索引 index
1 | create [unique] index R_index on R(name) |
连接 join
1 | select * |
自然连接 natural join
1 | select * |
using
要指定自然连接的依据,可以使用using
1 | select * |
inner join
内连接,不会保留含有属性值为null的记录
left/right/full outer join
外连接
以左外连接为例
1 | select * |
这样得到的记录中,会存在student的属性有记录而takes的属性为空的记录
视图 views
创建视图
1 | create view stuView(ID,name,avg_grade) as |
更新视图
1 | insert into stuView values |
此时,等同于对原表使用insert,但是相对于原表,视图中没有的属性将会表现为null,如(114514,‘Mike’,100,null)
权限
授予权限
1 | grant select on R to U1,U2 |
收回权限
1 | revoke select on R from U1,U2 |
如果有多个权限授予源,授予多次相同的权限,只收回一次权限并不会一次性去掉全部相同的权限
角色
1 | create role instructor |
事件
1 | create trigger credits_earned after update of takes on (grade) |




