
操作系统 期中复习(五至七章)
五 CPU调度
cpu调度的目的是为了提高CPU利用率
抢占式Preemptive & 非抢占式Nonpreemptive
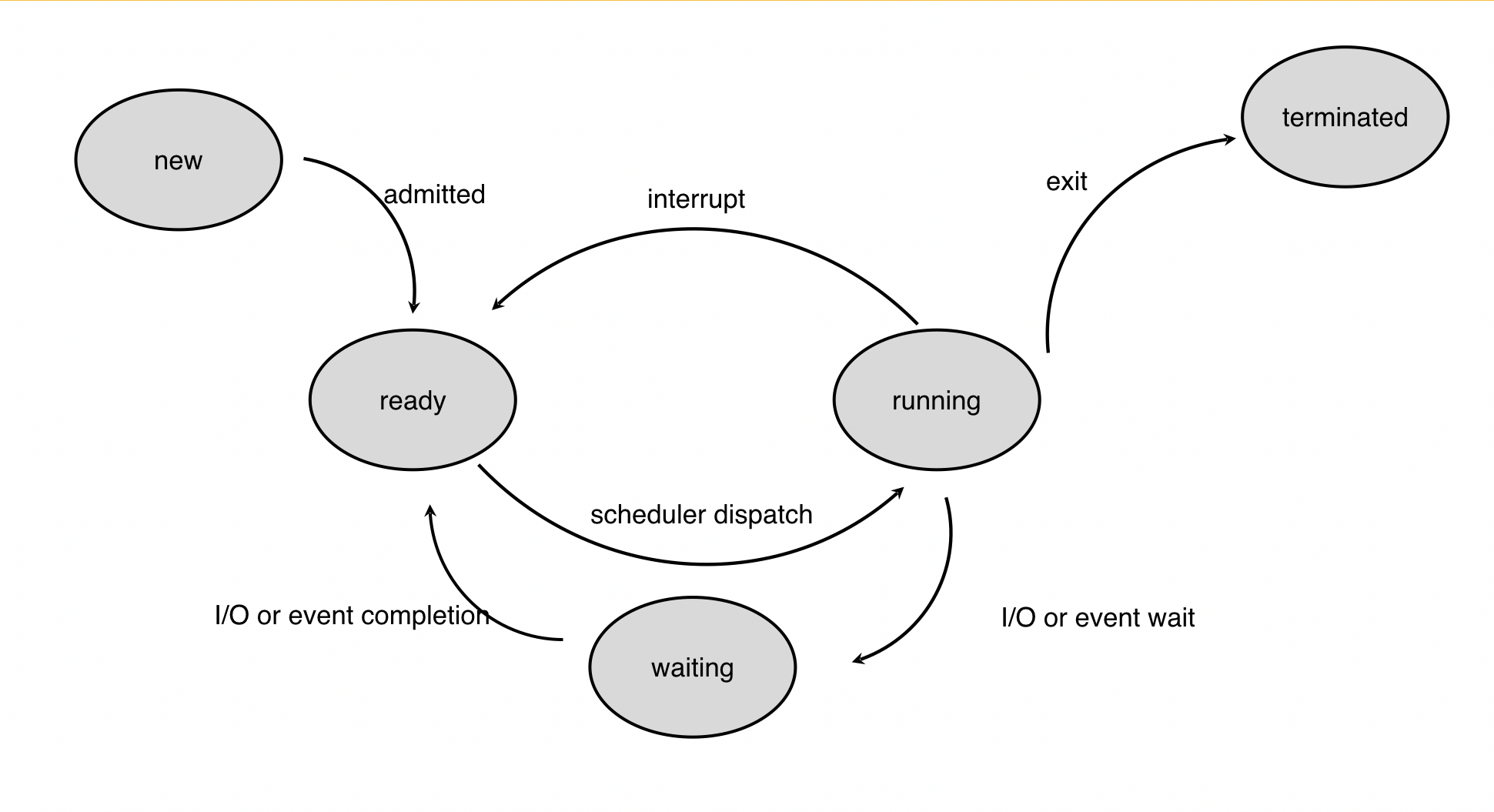
再一次回顾以上CPU流程阶段图,有四种可能的阶段转换会触发CPU调度
- running -> waiting
- running -> terminated
- running -> ready
- waiting -> ready
在这其中,由running和waiting转换到ready的操作是抢占式的,而剩下的为非抢占式的
也就是说,抢占式会导致进程被中断,回到就绪态;而非抢占式会阻塞进程运行,使其进入等待态
衡量标准
CPU利用率
吞吐量 Throughput
单位时间内完成作业的数量
周转时间 Turnaround time
进程从被创建到终止的总共时长
可以使用进程的终止时刻 - 创建时刻,得到周转时间
平均周转时间(操作系统更在乎)
带权周转时间
平均带权周转时间
等待时间 Waiting time
进程等待运行的时间
可以使用进程的终止时刻 - 创建时刻 - 运行时长,得到等待时间
响应时间 Response time
进程从被创建起第一次被唤起运行的等待时间
可以使用进程第一次运行时刻 - 创建时刻,得到响应时间
调度算法
FCFS 先来先服务
先来的进程先执行
SJF 短作业优先调度算法
共有两种,抢占式与非抢占式
抢占式
抢占式的SJF会在一个时间片结束时,进行下一个进程的判断,以完成下一个作业运行时间较短的作为高优先级。若当前进程作业未完成而优先级较低的话,会中断当前进程的作业,转而进行高优先级进程作业
抢占式的短作业优先调度算法也被称为Shortest-Remaining-Time-First (SRTF),最短剩余时间优先
非抢占式
非抢占式的SJF会在一个时间片结束时,进行下一个进程的判断,以完成下一个作业时间较短的作为高优先级。
SJF是追求平均等待时间最短的最优选择算法
存在的问题是如果一直存在比自己运行时间短的进程,那么自己永远不会执行,也就是饥饿问题
CPU运行时间预测
优先调度算法 Priority Scheduling
一个优先数负责进程的优先级,数字越小,级别越高或者数字越大,级别越高
同样有抢占和非抢占式
可以认为,SJF是CPU主动根据剩余最短时间优先级调度的特例
解决饥饿问题的方法
-
随程序存在时间的增长,程序的优先级会动态增加,可以解决SJF的饿死问题
-
但同时可能会增加CPU计算优先级的损耗,CPU利用率下降
RR 轮转调度算法 (round robin)
核心思想是一个进程不能连续占用超过一个时间片,除非当前只有一个进程
也就是说,RR算法是抢占式的
时间片到了之后都要切换进程,就算是同一个进程都要切换
对于一个进程,
-
如果运行时长大于一个时间片,那么当时间片结束时,会中断当前进程,转向下一个进程
-
如果运行时长小于一个时间片,那么会执行完这个进程后,CPU会直接交给下一个进程执行
也就是说,不是以时间片为最小时间单位,如果一个进程时长小于时间片,那么无需等待当前时间片长度时间就可以切换到下一个进程
如果就绪队列有n个进程,并且时间片为q,那么每个进程会得到1/n的CPU时间,而且每次分得的时间不超过q个时间单元。每个进程等待获得下一个CPU时间片的时间不会超过(n-1)q个时间单元。
例如,如果有5个进程,并且时间片为20ms,那么每个进程每100ms会得到不超过20ms的时间。
多级队列调度
可以采用前后台分离的进程队列
- 前台为交互式队列,采用RR算法
- 后台为批处理队列,采用FCFS算法
队列之间的调度可以是固定优先级调度,如前台优先级一定高于后台
多级反馈队列调度
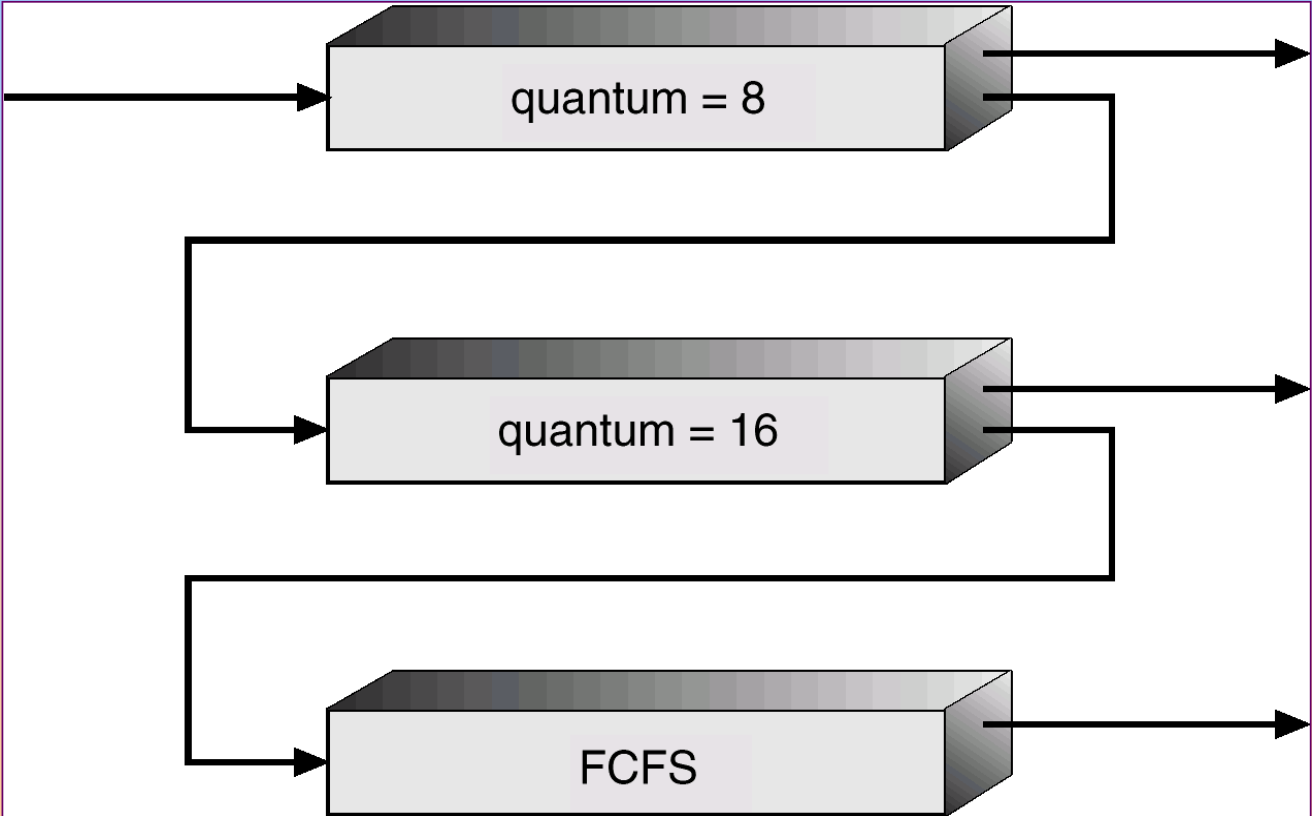
多级反馈队列调度算法允许进程在队列之间迁移,根据不同CPU执行的特点来区分进程
-
如果进程使用过多的CPU时间,那么它会被移到更低的优先级队列
-
将IO密集型和交互进程放在更高优先级队列上
-
在较低优先级队列中等待过长的进程会被移到更高优先级队列,这种形式的老化(aging)会阻止饥饿问题的发生
-
如果高优先级的队列有进程到达,那么低优先级的队列内进程会被中断,先进行高优先级队列进程
六 同步
为了维护协作进程下的数据一致性,需要建立进程同步以解决共享数据并发访问的问题,确保共享同一逻辑地址空间的协作进程的有序执行
引入
回顾进程协作时的生产者-消费者问题,为了解决实际缓冲只有BUFFER_SIZE - 1的问题,可以引入一个count变量,来记录缓冲区内的实际占有数量。
然而,这一引入会因为生产者进程和消费者进程的并发执行带来问题。
count++和count--不是原子操作,也就是说,以上操作会被抢夺中断。
1 | register = counter |
假设存在生产者和消费者各存在自己的寄存器R1、R2,那么当以上赋值操作执行被中断时,count的值是不确定的,因为生产者和消费者的进程执行次序是不确定的。
所以,需要进程同步(process synchronization)与进程协调(process coordination)
临界区
当一个进程在临界区内执行时,另外的进程不允许在它们的临界区内执行。
1 | do { |
临界区问题的解决方案需要符合以下三条
-
互斥(mutual exclusion)
不能同时有两个进程在临界区中
-
进步(progress)
当需要有进程进入临界区时,那么只有当前不在剩余区内执行的进程可以参加选择,这种选择不能无限推迟
-
有限等待(bounded waiting)
从一个进程发出进入临界区的请求直到这个请求允许为止,其他进程允许进入其临界区的次数是有限的
对于非抢占式内核,临界区不会发生竞争
对于抢占式内核,需要设计解决方案以阻止竞争的发生
Peterson 解决方案
定义
flag表示准备进入临界区的进程,初始状态均为falseturn表示允许在临界区中执行的进程
1 | // 进程Pi |
1 | // 进程Pj |
硬件同步
基于**加锁(locking)**来保护临界区
单处理器可以在共享变量被修改时禁止中断出现,防止被抢占,这种方法为非抢占式内核采用
但到了多处理器上,中断禁止的传递需要时延损耗。所以,应通过特殊的原子指令来解决临界区问题。
以下介绍两种原子指令解决临界区问题
test_and_set
1 | bool test_and_set(bool *target) { |
1 | do { |
当初始化lock为假时,这个while循环就会被跳过,然后上锁。直到当前进程解锁前,其他进程都无法进入临界区
swap
1 | void swap(bool *a,bool *b) { |
1 | while(true) { |
lock为共享变量,而key为进程私有变量
当初始化lock为假时,这个while循环会进行一次交换,使得lock为真。直到当前进程解锁前,其他进程都无法进入临界区
互斥锁(mutex lock)
一个进程在进入临界区时通过acquire()获得锁,退出临界区时通过release()释放锁。
为了区分当前锁能否被获得,创建一个锁特有的available布尔变量来表示锁是否可用
1 | void acquire() { |
1 | void release() { |
以上Peterson、硬件同步、互斥锁都有一个共同的问题,就是在临界区有进程进入的情况下,另一个进程会一直循环while,造成时间片浪费,也就是忙等待
信号量 semaphore
信号量的提出是为了解决忙等待问题
它的两个原子操作如下
-
wait()或P1
2
3
4
5
6void wait(S) {
while(S <= 0) {
// busy wait
}
S--;
} -
signal()或V1
2
3void signal(S) {
S++;
}
一般可以这样做
1 | // process 1 |
当然,也可以这样
1 | do { |
信号量存在死锁和饥饿问题
如果要细化信号量的实现,可以定义以下信号量结构
1 | typedef struct { |
那么wait和signal操作会变成这样子
1 | void wait(S) { |
实际上,信号量只是将忙等待从进入区移动至临界区,但是临界区等待的时间很短
信号量典例
生产者-消费者问题(有界缓冲问题)
现在让我们用信号量实现生产者-消费者问题
1 | semaphore mutex = 1 |
1 | // 生产者 |
1 | // 消费者 |
可以看出,信号量实际上起到了抢占、释放资源的作用
读者-作者问题
对于一个数据库,可以同时有多个读者读,但只能有一个作者写;并且,作者和读者不能同时访问数据库
也就是说,要求作者在写入数据库时,拥有共享数据库独占访问权
可能的情况有
- 读者不会因为有作者等待就保持等待,而是直接进入开始读
- 一个作者等待,就不会有新的读者开始读
这里讨论的是第一种情况
1 | public: |
1 | // 作者进程 |
1 | // 读者进程 |
可以发现,要修改公共值或进行互斥操作时,总要经过
-
抢资源(wait)
-
执行操作
-
释放资源(signal)
哲学家就餐问题 dining-philosophers problem
在多个进程间分配资源,并且不会出现死锁和饥饿
n个哲学家围绕圆桌而坐,他们手旁各有一支筷子。只有同时拿起两只筷子才能就餐。
1 | semaphore chopstick[n]; |
1 | // 每个哲学家进程 |
这样的操作可能会带来死锁问题,即每个哲学家同时拿起右边的筷子
管程 Monitor
定义以下结构
1 | monitor M { |
在管程结构中,确保了只有一个进程能处于活动状态
还可定义condition类型的变量,作为同步条件
对于同步条件变量,可以进行wait()和signal()操作,注意此时的操作意义是“挂起”和“恢复”,而不是进行什么变量的加减操作,要与信号量区分开。
哲学家就餐问题的管程解决方式
1 | monitor DiningPhilosophers { |
然后,每个哲学家可以按以下步骤操作
- 调用
pickup()拿起筷子 - 用餐
- 调用
putdown()放下筷子
管程可以确保相邻两个哲学家不会同时用餐,防止死锁,但无法解决饥饿问题
七 死锁
死锁成立条件
四个条件必须同时成立,才能死锁
- 资源必须互斥 mutual exclusion
- 进程需要占有资源并等待
- 循环等待
- 进程不能剥夺已被其他进程占有的资源(非抢占)
操作系统的解决措施
- 通过协议预防或避免死锁
- 允许系统进入死锁状态,检测到后恢复
- 忽视这个问题,认为死锁不会发生(交给创造问题的对象去解决)
每个进程会依次按以下步骤处理资源:
- 请求
- 使用
- 释放
资源分配图
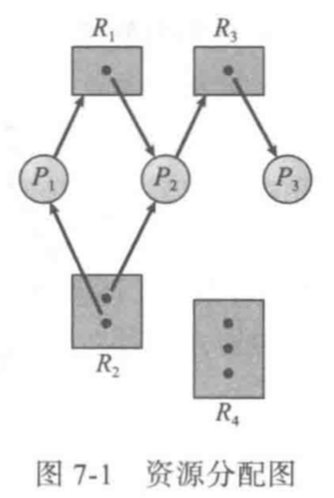
可以通过资源分配图这一有向图来描述死锁
图中元素有
- P:进程
- R:资源类型,点表示一个资源类型拥有的资源实例
- 有向边:申请边
- 有向边:分配边
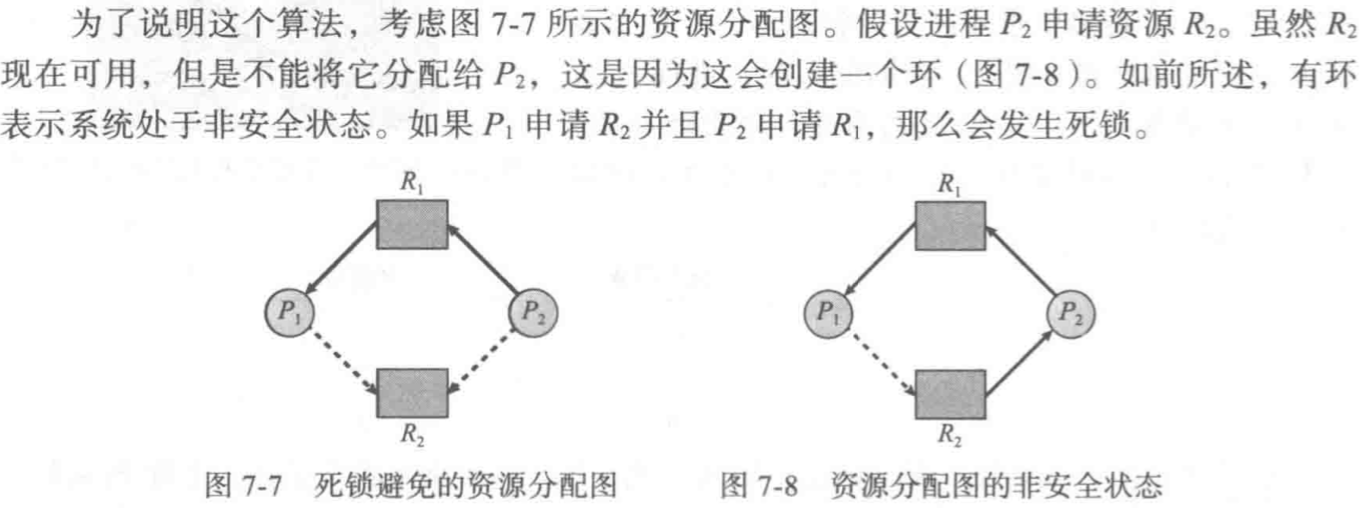
可以证明的是,当图中出现有向环时,可能有死锁发生,没有环时,一定不存在死锁
具体来说,当环上的资源类型都只有一个资源实例时,死锁发生;如果环上的资源类型有多个资源实例,那么死锁是有可能的/
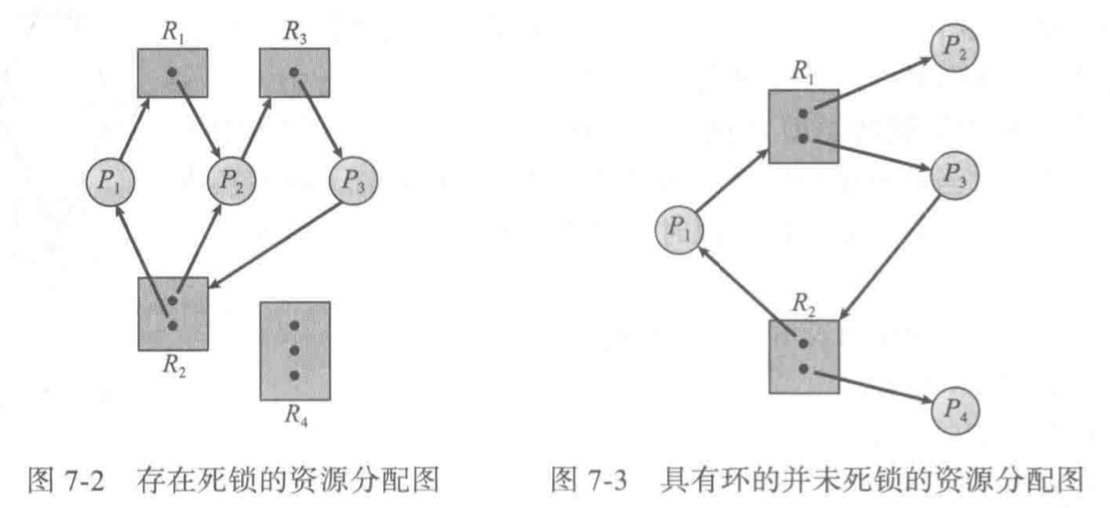
死锁避免:安全状态与安全序列
存在一个安全进程序列,其中的进程依次执行,不会发生死锁
即使当前申请的资源不能立即可用,那么可以等待直到占有资源全部中释放。
非安全状态不一定会死锁
这种方案会使得资源利用率变低
资源分配图算法
适用于资源类型只有一个实例的分配
我们可以在资源分配图中引入需求边,表示进程P可能在将来申请资源R。
需求边类似同一方向的申请边,但是用虚线表示。
规定,只有在进程P的所有边都为需求边时,才能允许将需求边加入图中
当进程申请时,只有在将申请边变成分配边且不会形成环时,才能允许申请
银行家算法
适用于每种资源类型有多个实例的资源分配系统
实际上,就是对形如
| Process | Allocation | Max | Need | Available |
|---|---|---|---|---|
| P0 | 0 1 0 | 7 5 3 | 7 4 3 | 3 3 2 |
| P1 | 2 0 0 | 3 2 2 | 1 2 2 | |
| P2 | 2 3 2 | 4 3 3 | 2 0 1 |
- 可以对P1申请的资源予以分配,P1完成后,可用量为3 2 2
- 然后对P2申请的资源予以分配,P2完成后,可用量为4 3 3
- 此时P0无法满足,转入非安全状态
实际上此时死锁
要分配资源给一个进程,需经历以下步骤:
- 进程提出申请量(A,B,C)
- 若申请量不超过当前需求量,进行下一步
- 若申请量不超过当前可用量,进行下一步
- 进行假设的资源分配
- 如果此时新的系统状态是安全的,那么可以允许请求执行
- 如果不是安全的,那么不能允许
死锁检测
每种资源类型只有单个资源实例
可以将资源分配图变形成为等待图,通过删除所有资源类型点,合并适当边,就可以做到
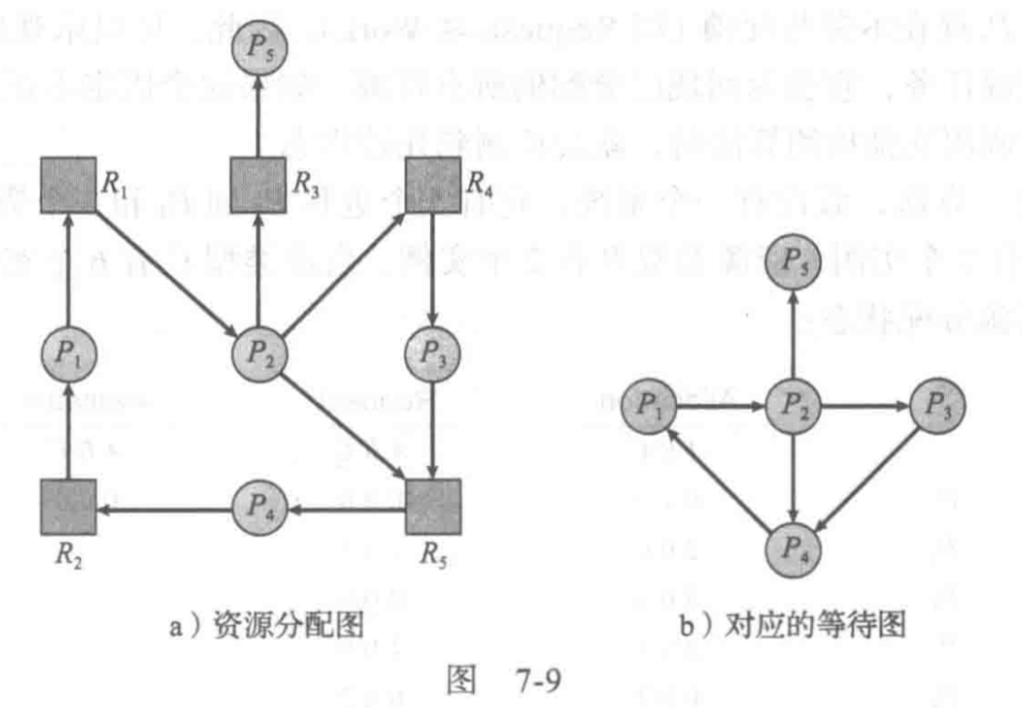
当且仅当等待图中有一个环,系统死锁
每种资源类型有多个实例
可以通过改造银行家算法满足要求
-
设
Work和Finish分别为长度为m和n的向量初始化
Work= Available。对
Finish[i],如果,那么Finish[i]= false,反之为true -
若不存在
i满足Finish[i] = false
跳转第4步
-
Finish[i] = true跳转第2步
-
如果此时
Finish[i] = false,那么就是进程死锁
死锁恢复
- 人工处理
- 中止死锁进程
- 从死锁进程抢占资源(小心造成饥饿问题)



